Há muito tempo a escrita é uma das principais ferramentas da comunicação humana. Mas na Era Digital, esse meio de registrar ideias e sentimentos atingiu um novo potencial. Com a ascensão da Internet, artigos científicos, textos publicitários e jornalísticos não ficam mais apenas no papel, estão disponíveis em qualquer meio digital. Essa numerosa quantidade de textos gera um banco de dados riquíssimo, que pode ser base para diversas análises. Mas, como realizar estas análises?
Uma das principais técnicas utilizadas para extrair informações de documentos textuais é a mineração de texto. Esta representa uma importante ferramenta de suporte para aqueles que buscam entender informações contidas nesses documentos. Uma multiplicidade de áreas podem ser cruzadas através desse mecanismo, desde as mais particulares, como a análise de um texto de Shakespeare, até a prevenção de cybercrime.
Dentro da mineração de texto, há diversos tipos de análises que vão de acordo com o interesse de cada pesquisador ou analista. Um dos principais interesses é descobrir quais tópicos são os mais recorrentes dentro do corpo de diferentes documentos. Por exemplo, conhecer quais são os assuntos mais tratados em um jornal ao longo de um período de tempo. Para isso, uma das técnicas mais populares é a rede bayesiana hierárquica Latent Dirichlet Allocation (LDA), que relaciona palavras por meio de tópicos latentes. Neste modelo cada documento é amostrado a partir de uma mistura aleatória de tópicos, em que para qualquer tópico é considerada uma distribuição Multinomial sobre cada palavra.
No modelo LDA é necessário especificar o número de tópicos de interesse. Cada palavra é atribuída aleatoriamente a um tópico, recebendo uma pontuação baseada na probabilidade dessa palavra pertencer ao tópico no conjunto de documentos. Essa palavra é atribuída a outro tópico e a mesma pontuação é calculada. Após esse processo iterativo, obtém-se uma lista de palavras em cada um dos tópicos com probabilidades associadas. Assim, podemos selecionar as k palavras com maior probabilidade de pertencer a um tópico em particular e, a combinação destas palavras permite descrever o tópico.
Blei (2012) afirma que essas palavras tendem a coexistir juntas no mesmo contexto e as palavras com alta frequência terão posições maiores em cada tópico. No LDA, um conjunto de documentos compartilham o mesmo conjunto de tópicos, porém em cada documento, as proporções são diferentes para tais tópicos. A teoria mais detalhada pode ser encontrada em Blei (2003).
Para exemplificar, realizamos uma análise textual dos artigos de dois veículos: os jornais Valor Econômico (brasileiro) e Portafolio (colombiano). Nos dois jornais, selecionamos artigos publicados no período de janeiro a abril de 2019 da seção Finanças, que em geral tratam de temas financeiros nacionais e internacionais. No Valor Econômico, selecionamos 2470 artigos e do Portafolio, 759. Em ambos os casos, os artigos foram de acesso público. Posterior à seleção dos artigos e do processo de depuração nos textos, foi aplicada a função LDA do software estatístico R. Nosso interesse neste caso é conhecer os quatro principais tópicos em cada jornal.
Valor Econômico
Para o jornal Valor Econômico, pela modelagem LDA os resultados obtidos, considerando quatro tópicos, são
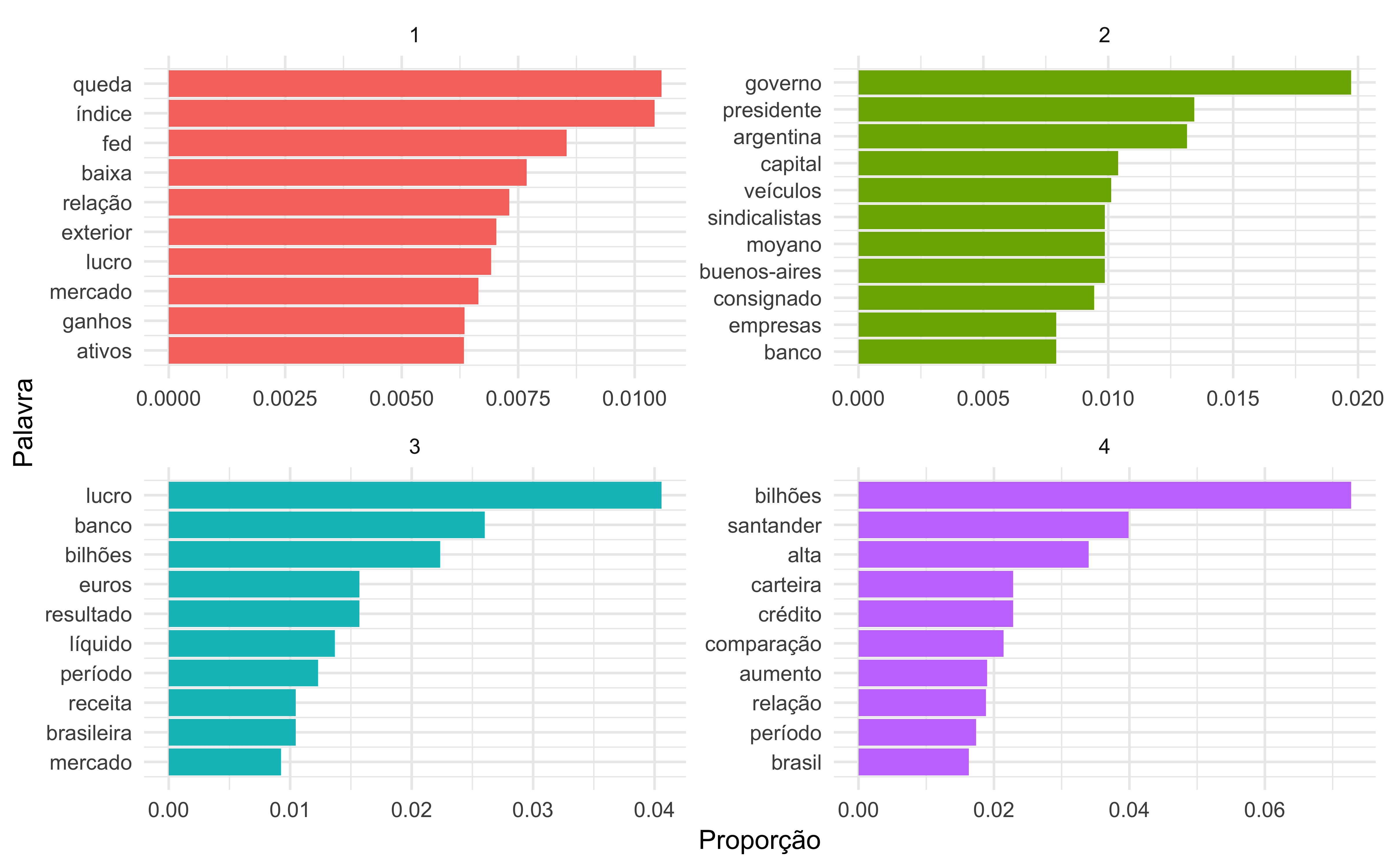
A Figura 1 nos permite entender os tópicos que foram extraídos dos artigos. As palavras mais comuns no tópico 1 incluem “queda”, “indice”,“fed” “lucro” e “exterior”, o que sugere notícias sobre alguma queda influenciada pelo Federal Reserve. O tópico 2 inclui “presidente”, “governo”, “Argentina” e “sindicalistas” sugerindo notícias sobre algum evento sindical ocorrido na Argentina. No tópico 3, as palavras “lucro”, “banco”, “mercado” e “brasileira” apontam para notícias sobre o mercado financeiro brasileiro. Por fim, o tópico 4 indica notícias sobre resultados do Banco Santander.
Uma observação importante sobre as palavras em cada tópico é que algumas delas, como “bilhões”, “banco” e “alta”, são comuns em mais de um tópico. Esta é uma vantagem da modelagem LDA em oposição a outros métodos que não podem ter alguma sobreposição em termos de palavras.
Dado que conhecemos a probabilidade β de uma palavra pertencer a um tópico específico, podemos comparar as probabilidades entre os tópicos. Esta comparação pode ser feita baseada no logaritmo da razão das probabilidades, estimada por log2(βi/βj), em que (i,j) representa o número do tópico. Para mais detalhes ver Silge and Robinson (2019).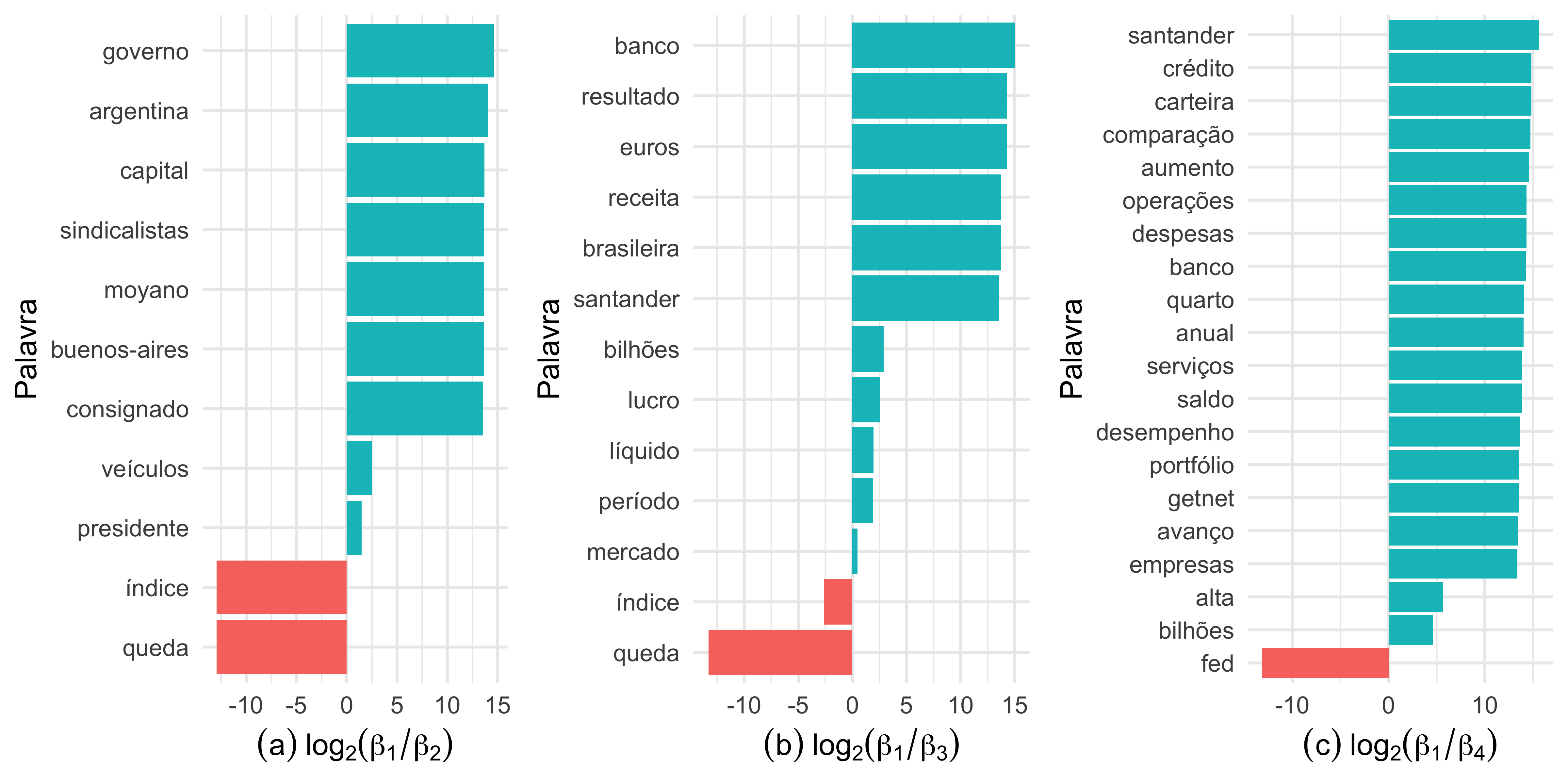
Na Figura 2 , ao comparar os tópicos 1 e 2, os termos mais frequentes no primeiro são “queda” e “indice”. Já no tópico 2, as palavras que mais se repetem são “governo”, “argentina” e “sindicalistas”. Essa diferença valida a ideia de que eles tratam temas distintos. É possível inferir ainda, ao ver a presença dos termos “mercado”, “período” e “índice” nos tópicos 1 e 3, que estes são mais similares. Os tópicos 1 e 4, assim como no primeiro caso, parecem tratar de temas diferentes.
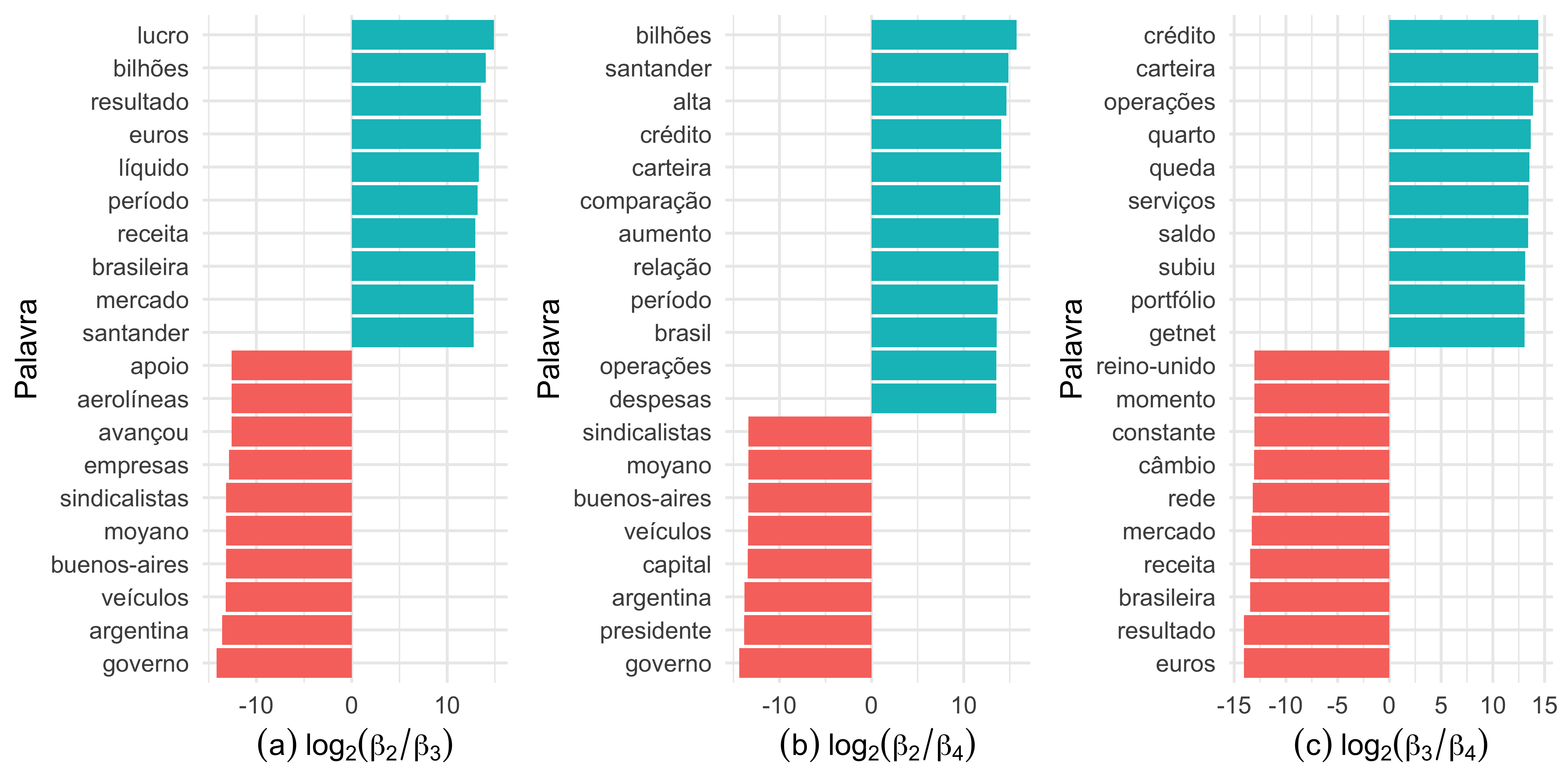
Nos gráficos da Figura 3 vemos que os tópicos 2, 3 e 4 não compartilham muitos termos, isso corrobora com o mostrado no gráfico da Figura 1, que eles tratam de temas diferentes.
Portafolio
Do mesmo modo que no Valor Econômico, determinamos as palavras mais recorrentes dentro de 4 tópicos no conteúdo da seção finanças do jornal Portafolio. Pela modelagem LDA, os resultados obtidos são
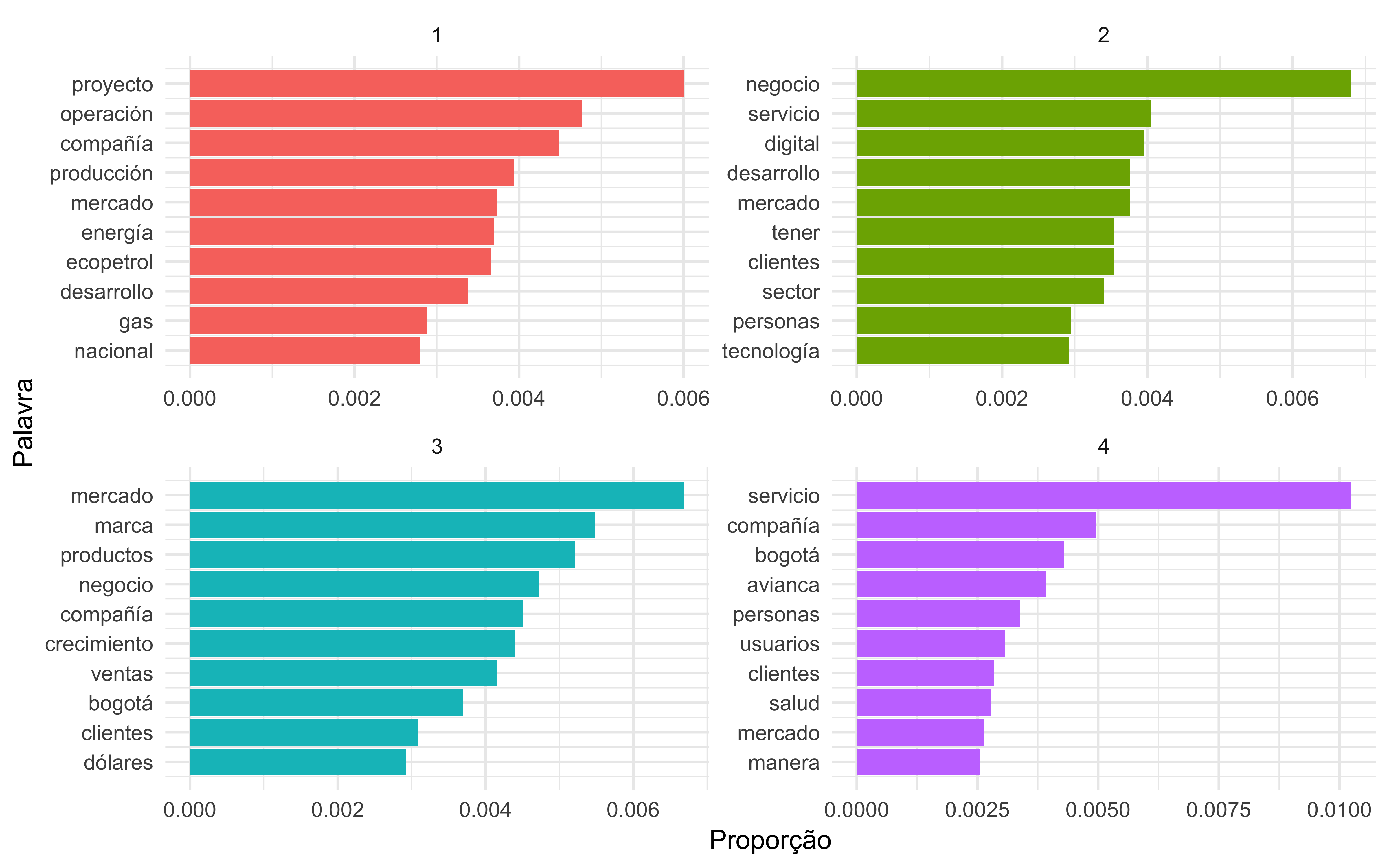
A Figura 4 nos permite entender os tópicos que foram extraídos dos artigos. As palavras mais comuns no tópico 1 incluem “proyecto”, “ecopetrol”,“compañia”, “energia” e “gas”, sugerindo notícias relacionadas a algum projeto energético da Ecopetrol. Os termos “negocio”, “servicio”, “digital” e “tecnologia”, presentes no tópico 2 nos levam a entender que este tópico engloba notícias sobre serviços ou projetos digitais e tecnológicos. No tópico 3, as palavras “mercado”, “productos” e “bogotá” sinalizam notícias sobre negócios de companhias da capital colombiana. O último tópico novamente traz a palavra “servicio” e “bogotá” agora acompanhada de “compañia” e “avianca”, mostrando estar relacionada a notícias referentes aos serviços da companhia aérea em Bogotá.
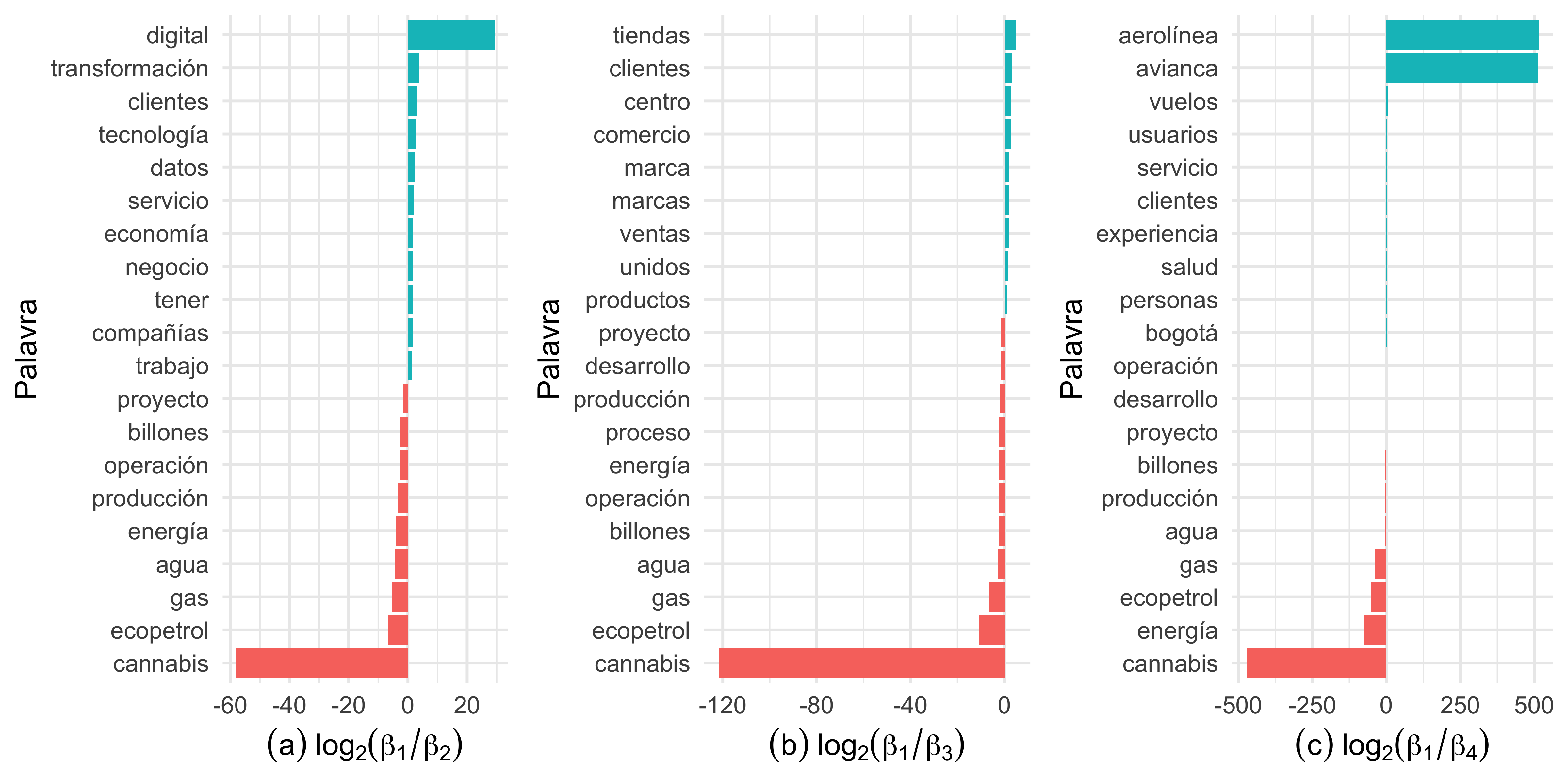
Da Figura 5(a), notamos que os tópicos 1 e 2 compartilham muitos termos, porém o tópico 1 parece tratar de algum tema relacionado a cannabis enquanto que o tópico 2 está relacionado a assuntos digitais. Da mesma forma, os tópicos 1 e 3 se diferenciam pela palavra cannabis. Já nos tópicos 1 e 4 enxergamos uma grande semelhança, diferenciando-se pelas palavras “aerolínea” e “avianca”, que têm uma maior probabilidade de pertencer ao tópico 4.
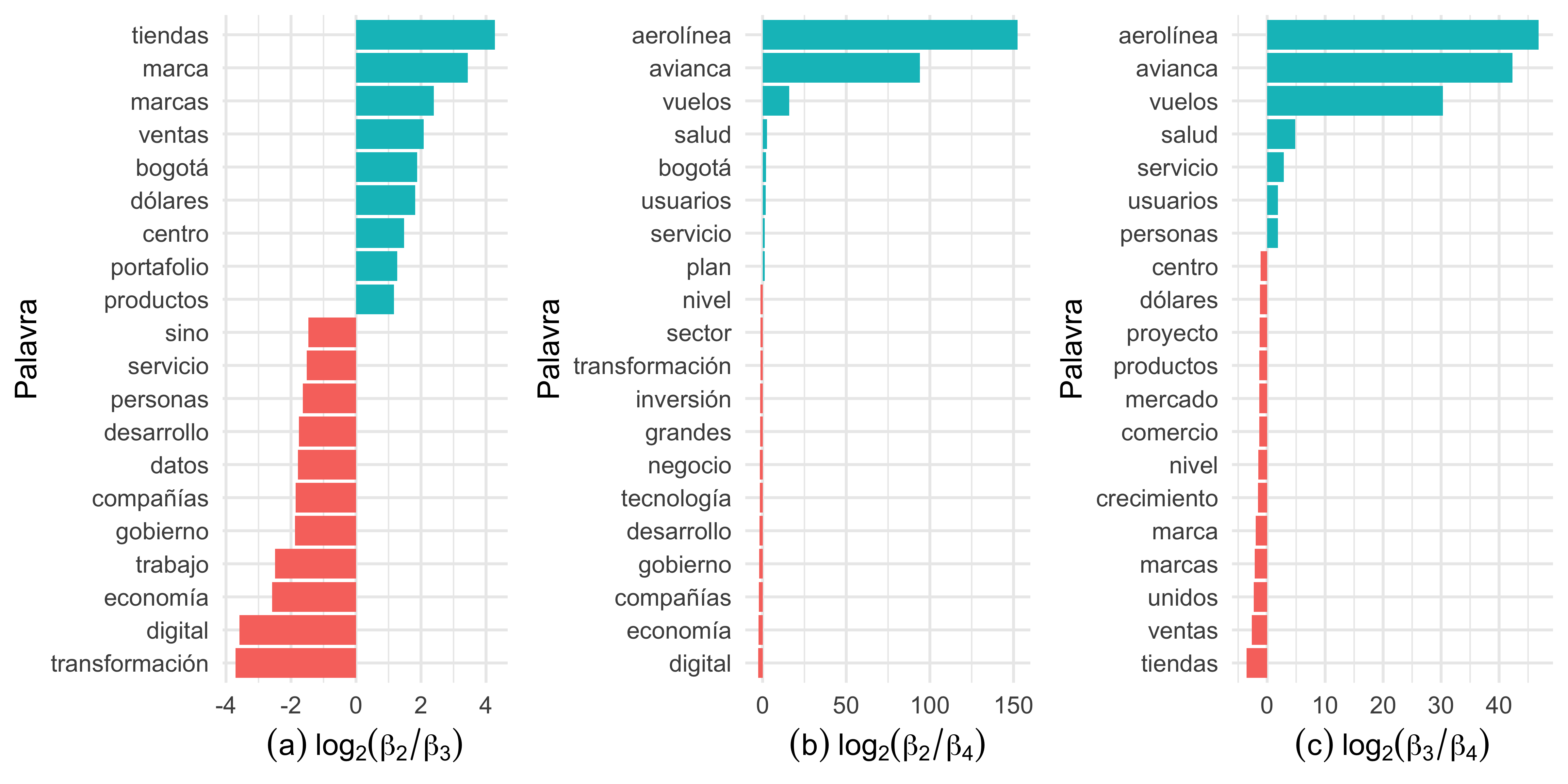
O gráfico da Figura 6(a) mostra que os termos presentes nos tópicos 2 e 3 não são compartilhados. Termos como “ventas”, “tiendas” e “bogotá” caracterizam temas relacionados a negócios e comércio na cidade de Bogotá. Já os termos “digital”, “economia” e “transformación” fazem alusão a temas de serviços tecnológicos. Nos gráficos da Figura 6(b) e 6(c) vemos que os tópicos compartilham a maioria das palavras, com exceção das palavras “aerolínea”, “avianca” e “vuelos”, que mostram uma maior probabilidade de pertencer ao tópico 4.
| Posição | Valor Econômico | Portafolio |
|---|---|---|
| 1 | alta | compañía |
| 2 | bilhões | negocio |
| 3 | lucro | mercado |
| 4 | banco | productos |
| 5 | santander | servicio |
Apresentamos aqui uma análise mais descritiva dos textos contidos nos dois jornais. Poderíamos ter analisado a correlação entre termos ou ainda, dada a presença de uma palavra, qual a probabilidade de outra ocorrer. Acompanhado de especialistas da área, inferências poderiam ser feitas e conclusões tiradas. A análise textual, do ponto de vista estatístico, é extensivamente ampla e o nosso interesse aqui foi apresentar uma das suas aplicações de forma simplificada.
Referências
[2] Silge J. and Robinson D., 2019, Text Mining with R.
[3] Blei D, Ng A, Jordan M, 2003, Latent Dirichlet Allocation, Journal of Machine Learning Research.
[4] Blei D, 2012, Probabilistic Topic Models, Communications of the acm.
Tradução
Veia Também
- Um estudo do preço de aluguel em Medellín por meio de um modelo de árvore de regressão
- Google Form: Importando dados em R e publicando resultados em AnalyStats-App
- Analisar dados do Youtube por meio do R e AnalyStats-App
- Analisar dados do Twitter por meio do R e AnalyStats-App
- R e AnalyStats-App juntos.