Hace mucho tiempo que la escritura es una de las principales herramientas de la comunicación humana. Pero en la era digital, ese medio de registrar ideas y sentimientos alcanzó un nuevo potencial. Con el ascenso de la Internet, artículos científicos, textos publicitarios y periodísticos no quedan sólo en el papel, están disponibles en cualquier medio digital. Esa numerosa cantidad de textos genera un banco de datos riquísimo, que puede ser base para diversos análisis. Pero ¿cómo realizar estos análisis?
Una de las principales técnicas utilizadas para extraer información de documentos textuales es la minería de texto. Esta representa una importante herramienta de soporte para aquellos que buscan entender la información contenida en estos documentos. Una multiplicidad de áreas pueden ser tocadas a través de ese mecanismo, desde las más particulares, como el análisis de un texto de Shakespeare hasta la prevención de cybercrimen.
Dentro de la minería de texto, hay varios tipos de análisis que van de acuerdo con el interés de cada investigador o analista. Uno de los principales intereses es descubrir qué temas son los más recurrentes dentro de un cuerpo de diferentes documentos. Por ejemplo, conocer cuáles son los asuntos más tratados en un periódico a lo largo de un período de tiempo. Para ello, una de las técnicas más populares es la red bayesiana jerárquica Latent Dirichlet Allocation (LDA), que relaciona palabras a través de tópicos latentes. En este modelo cada documento es muestreado a partir de una mezcla aleatoria de tópicos, en el que para cualquiera de ellos se considera una distribución Multinomial sobre cada palabra.
En el modelo LDA es necesario especificar el número de tópicos de interés. Cada palabra se asigna aleatoriamente a un tópico, recibiendo una puntuación basada en la probabilidad de que esa palabra pertenezca a él en el conjunto de documentos. Esa palabra es asignada a otro tema y se calcula la misma puntuación. Después de este proceso iterativo, se obtiene una lista de palabras en cada uno de los temas con probabilidades asociadas. Así, podemos seleccionar las k palabras con mayor probabilidad de pertenecer a un tópico en particular y, la combinación de estas palabras permite describir el tema.
Blei (2012) afirma que estas palabras tienden a coexistir juntas en el mismo contexto y las palabras con alta frecuencia tendrán posiciones más grandes en cada tema. En el LDA, un conjunto de documentos comparten el mismo conjunto de temas, pero en cada documento las proporciones son diferentes para estos temas. Una teoría más detallada puede ser consultada en Blei (2003).
Para ejemplificar, realizamos un análisis textual de los artículos de dos importantes diarios periodísticos: Valor Econômico (brasileño) y Portafolio (colombiano). En los dos diarios, seleccionamos artículos publicados en el período de enero a abril de 2019 de la sección finanzas, que en general tratan de temas financieros nacionales e internacionales. De el Valor Econômico, seleccionamos 2470 artículos y de el Portafolio, fueron seleccionados 759, en ambos casos artículos de acceso público. Después de la selección de los artículos y de un proceso de depuración en los textos, se aplicó la función LDA del software estadístico R. Nuestro interés en este caso es conocer los cuatro principales tópicos en cada diario.
Valor Econômico
Para el diario Valor Econômico, por el modelado LDA los resultados obtenidos, considerando cuatro tópicos, son
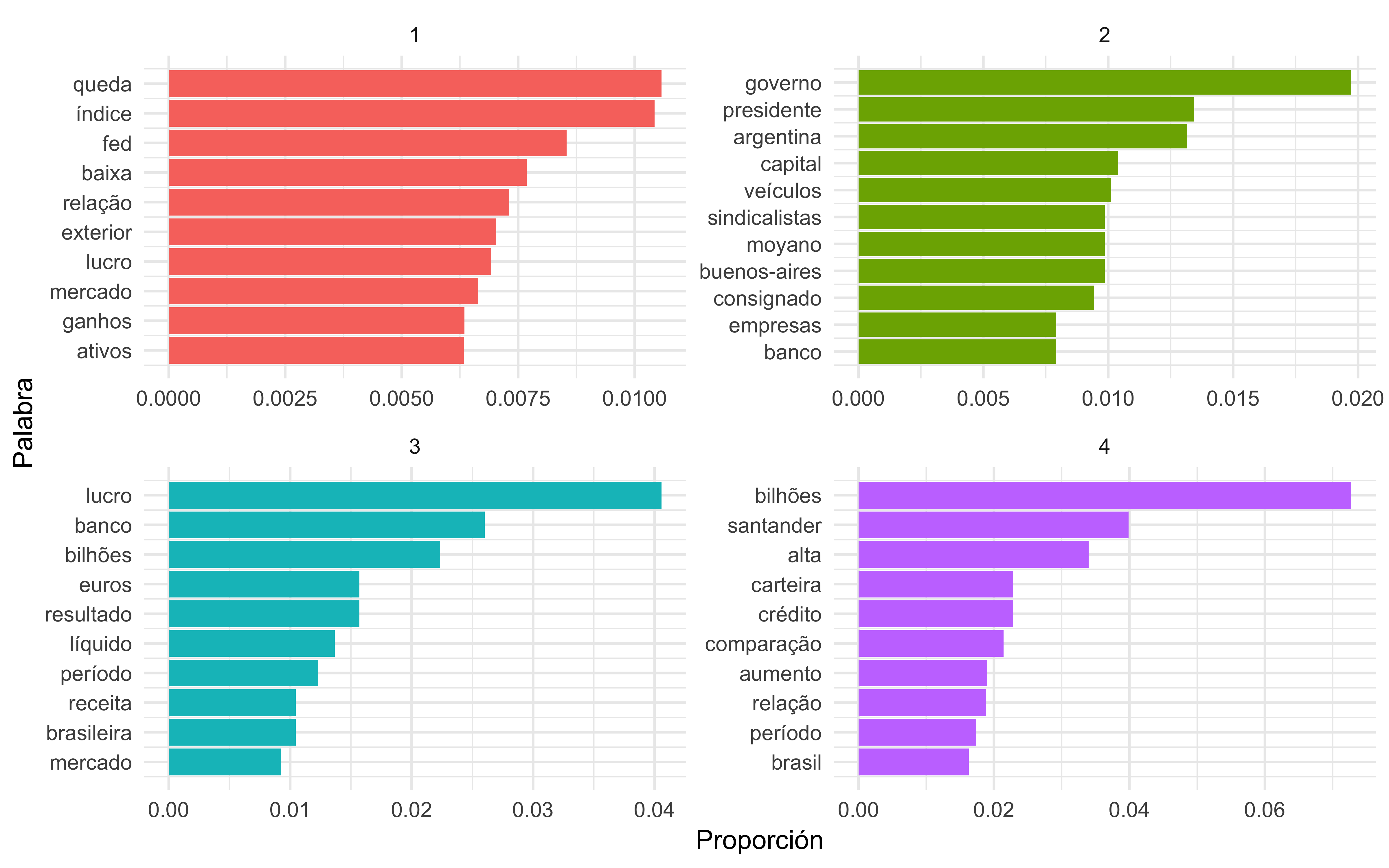
La Figura 1 nos permite entender los tópicos extraidos de los artículos. Las palabras más comunes en el tópico 1 incluyen “queda”, “indice”, “fed” “lucro” y “exterior”, lo que sugiere noticias sobre alguna caída influenciada por la Reserva Federal. El tópico 2 incluye “presidente”, “governo”, “argentina” y “sindicalistas” sugiriendo noticias sobre algún evento sindical ocurrido en Argentina. En el 3, las palabras “lucro”, “banco”, “mercado” y “brasileira” apuntan a noticias sobre el mercado financiero brasileño. Por último, el tópico 4 indica noticias sobre los resultados del banco Santander.
Una observación importante sobre las palabras en cada tópico es que algunas de ellas, como “bilhões”, “banco” y “alta”, son comunes en más de un tópico. Esta es una ventaja del modelado LDA en oposición a otros métodos que no permien tener una superposición en términos de palabras.
Dado que conocemos la probabilidad β de una palabra pertenecer a un tópico específico, podemos comparar las probabilidades entre ellos. Esta comparación puede hacerse basada en el logaritmo de la razón de las probabilidades, estimada por log2(βi/βj), donde (i, j) representan el número del tópico. Para más detalles ver Silge and Robinson (2019).

En la Figura 2, al comparar los tópicos 1 y 2, los términos más frecuentes en el primer tópico son “queda” e “indice” y en el 2, son “gobierno”, “argentina” y “sindicalistas”. Esta diferencia valida la idea de que tratan temas distintos. Es posible inferir aún, al ver la presencia de los términos “mercado”, “período” e “indice” en los tópicos 1 y 3, que éstos son similares. Los tópicos 1 y 4, así como en el primer caso, parecen tratar temas diferentes.
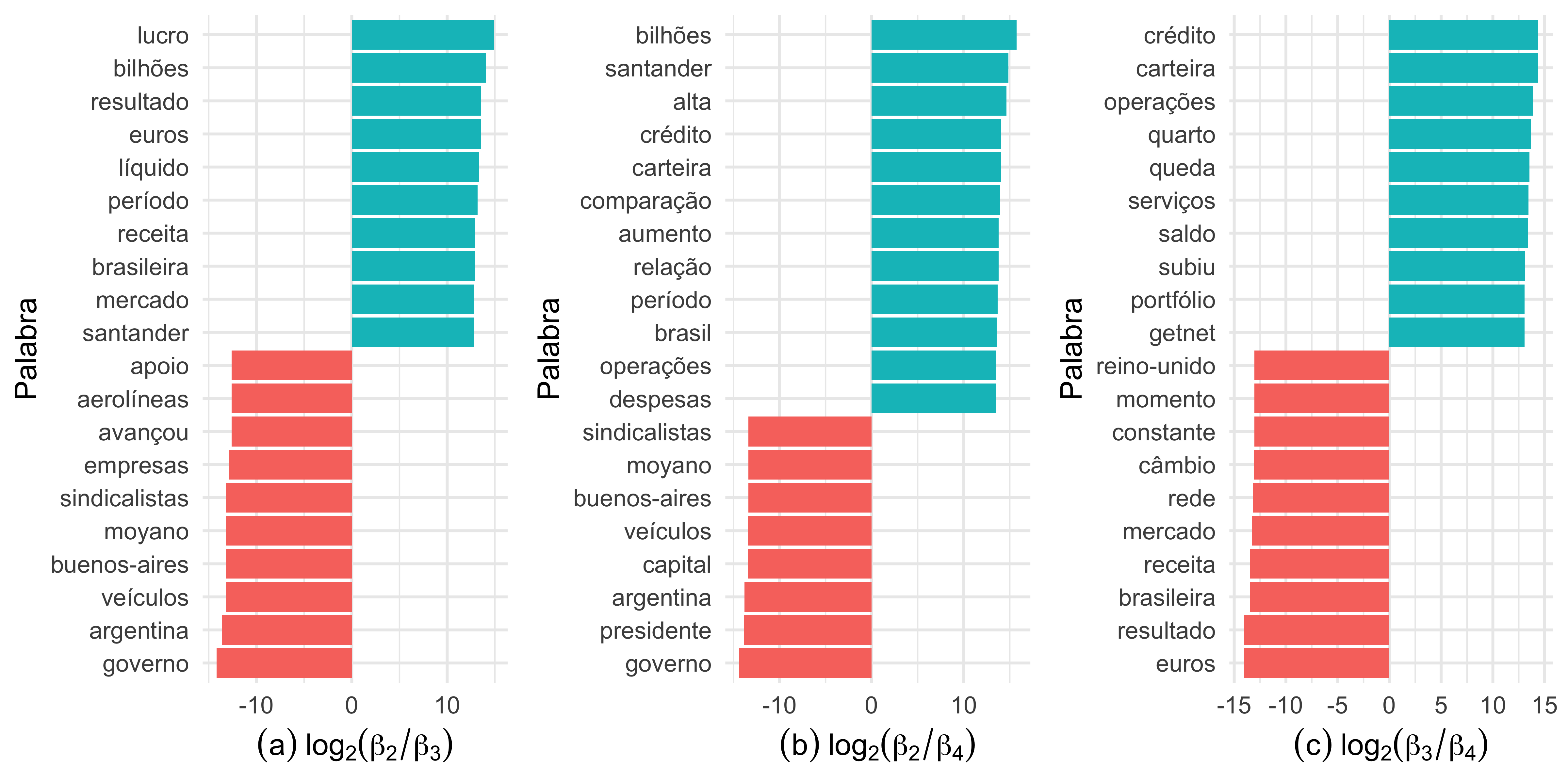
En los gráficos de la Figura 3 vemos que los tópicos 2, 3 y 4 no comparten muchos términos, esto corrobora con lo mostrado en la Figura 1, que tratan temas diferentes.
Portafolio
Al igual que en el análisis realizado con el diario Valor Econômico, determinamos las palabras más recurrentes dentro de 4 tópicos en el contenido de la sección finanzas del diario Portafolio. Los resultados obtenidos por el modelado LDA, son
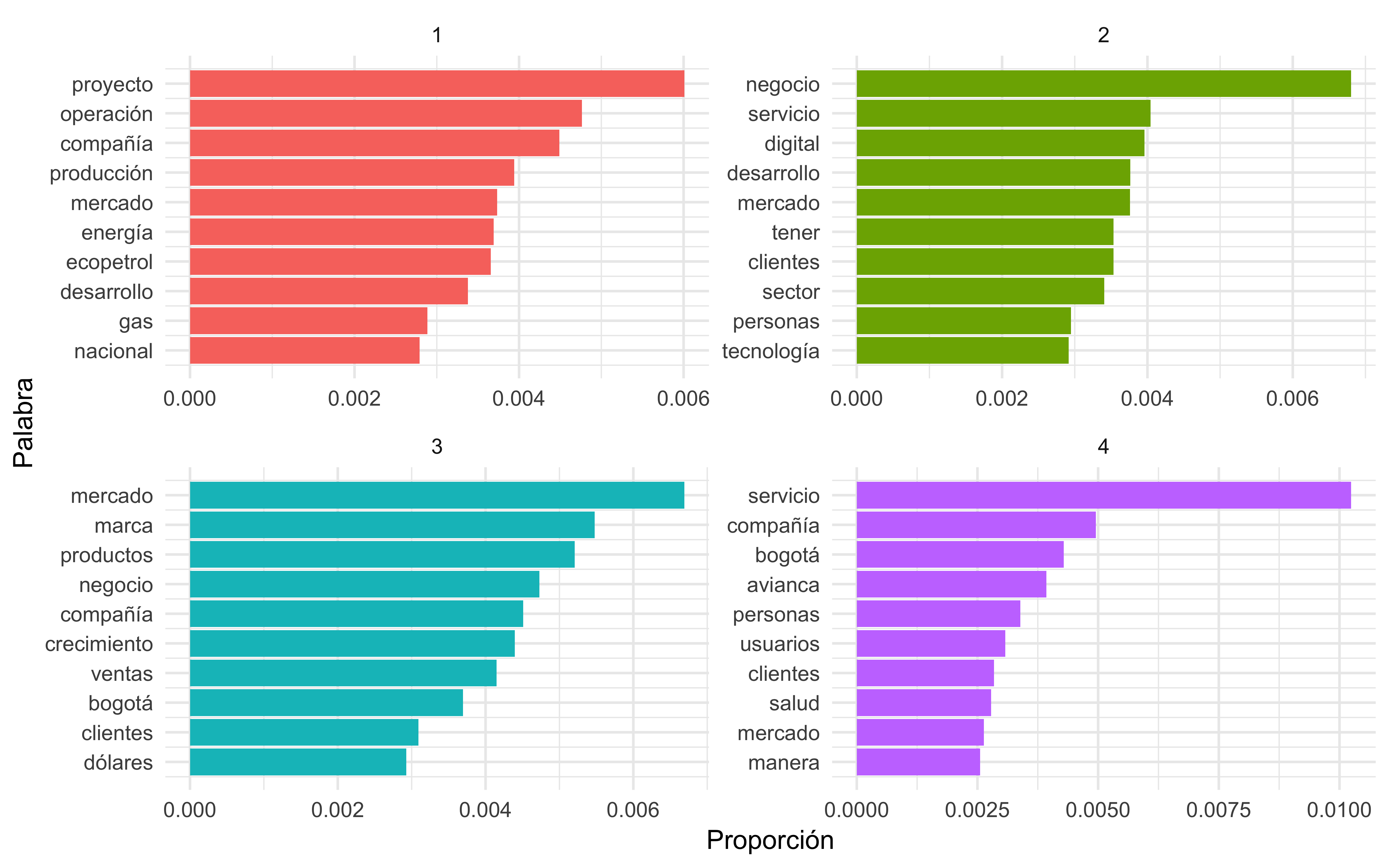
La Figura 4 nos permite entender los tópicos extraídos de los artículos. Las palabras más comunes en el tópico 1 incluyen “proyecto”, “ecopetrol”, “compañía”, “energía” y “gas”, sugiriendo noticias relacionadas con algún proyecto energético de Ecopetrol. Los términos “negocio”, “servicio”, “digital” y “tecnología”, presentes en el tópico 2 nos llevan a entender que este tópico engloba noticias sobre servicios o proyectos digitales y tecnológicos. En el punto 3, las palabras “mercado”, “productos” y “bogotá” señalan noticias sobre negocios de compañías en la capital colombiana. El último tópico nuevamente trae la palabra “servicio” y “bogotá” ahora acompañada de “compañía” y “avianca”, mostrando estar relacionada con noticias referentes a los servicios de la compañía aérea en Bogotá.

De la Figura 5(a), notamos que los tópicos 1 y 2 comparten varios términos, pero el tópico 1 parece tratar de algo más relacionado a “cannabis” mientras que el 2 está relacionado con temas digitales. De la misma forma, los tópicos 1 y 3 se diferencian por la palabra “cannabis”. En los tópicos 1 y 4 vemos una gran semejanza, diferenciándose apenas por las palabras “aerolínea” y “avianca”, que tienen una mayor probabilidad de pertenecer al tópico 4.
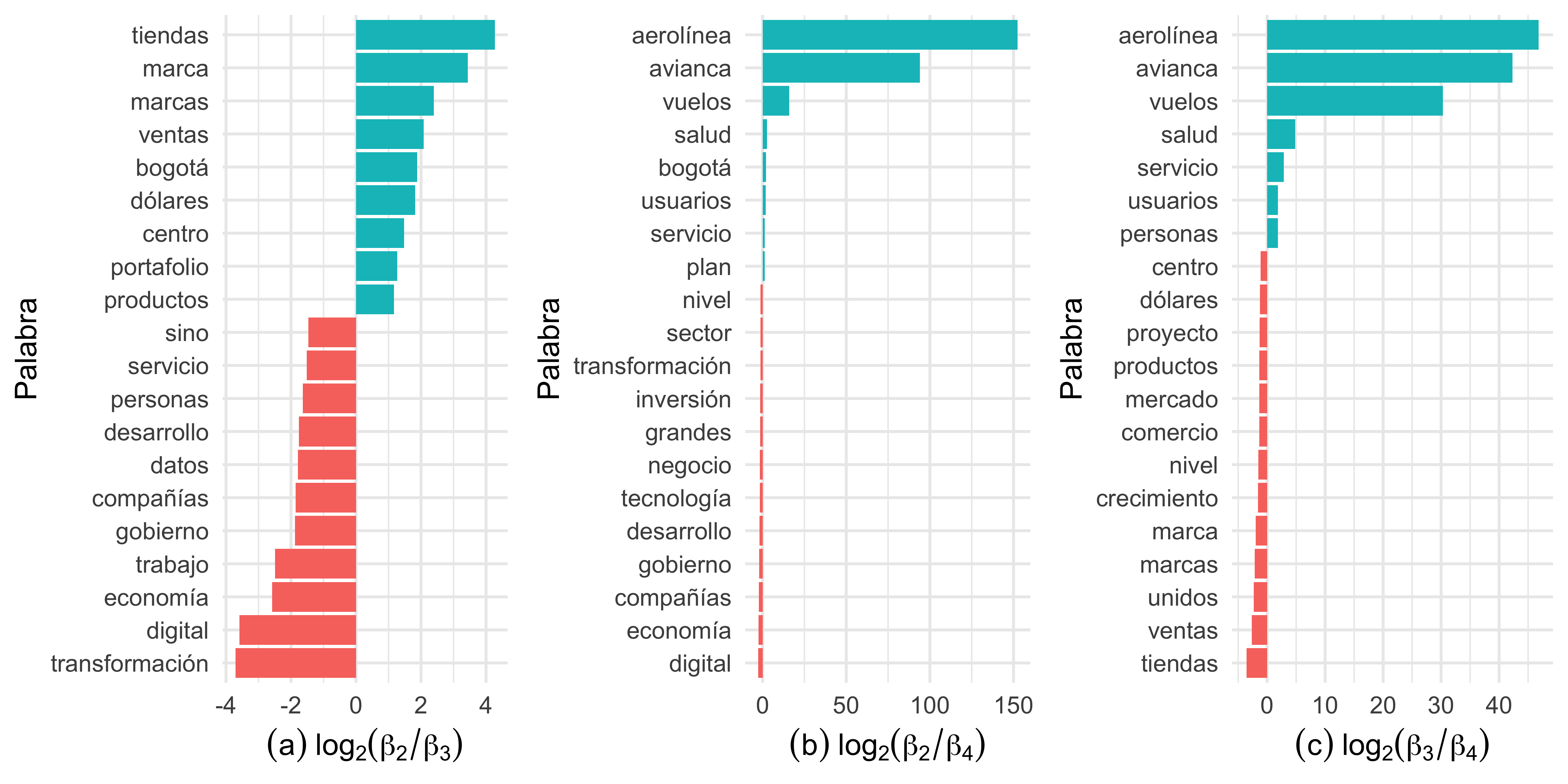
En la Figura 6(a) vemos que los términos en los tópicos 2 y 3 no se comparten. Los términos como “ventas”, “tiendas” y “bogotá” caracterizan temas relacionados con negocios y comercio en la ciudad de Bogotá. Los términos “digital”, “economía” y “cambio” hacen alusión a temas de servicios tecnológicos. En la Figura 6(b) y 6(c) vemos que los tópicos comparten la mayoría de las palabras, con excepción de las palabras “aerolínea”, “avianca” y “vuelos”, que muestran una mayor probabilidad de pertenecer al tópico 4.
| Posición | Valor Econômico | Portafolio |
|---|---|---|
| 1 | alta | compañía |
| 2 | bilhões | negocio |
| 3 | lucro | mercado |
| 4 | banco | productos |
| 5 | santander | servicio |
Presentamos aquí un sencillo análisis descriptivo de los textos contenidos en los dos diarios. Sin embargo, podríamos haber analizado la correlación entre términos o, dada la presencia de una palabra, cuál es la probabilidad de otra ocurrir. Acompañado de un especialista del área, podríamos obtener mejores inferencias y conclusiones más asertivas. El análisis textual, desde el punto de vista estadístico, es extensamente amplio y nuestro interés aquí fue presentar una de sus aplicaciones de forma resumida.
Referencias
[2] Silge J. and Robinson D., 2019, Text Mining with R.
[3] Blei D, Ng A, Jordan M, 2003, Latent Dirichlet Allocation, Journal of Machine Learning Research.
[4] Blei D, 2012, Probabilistic Topic Models, Communications of the acm.
Traducciones
Ver también
- Un estudio al precio de arrendamiento en Medellin por medio un modelo de arbol de regresion
- Google Form: Importando datos en R y publicando resultados en AnalyStats-App
- Analizar datos de Youtube a través de R y AnalyStats-App
- Analizar datos de Twitter a través de R y AnalyStats-App
- R y AnalyStats-App juntos.