Los investigadores usualmente en el proceso de recolección de datos se enfrentan con una gran cantidad de información textual, por tanto, el análisis de texto se convierte en un método importante para convertir datos no estructurados, en textos entendibles y con significado. Tiene como fin medir opiniones por medio de correos electrónicos, blogs, tweets, foros y otras formas de comunicación, para posteriormente obtener un análisis de tipo descriptivo o predictivo [1].
Dentro del análisis de texto encontramos diferentes metodologías; entre ellas el análisis de sentimiento (opinion mining), el cual es un método que se ha popularizado en los últimos años gracias al crecimiento de las redes sociales. Dicho análisis, consiste en ayudar a identificar y extraer información subjetiva del contenido en línea, que se utiliza para determinar actitudes, opiniones, y emociones expresadas por la opinión pública sobre unos temas específicos. En términos más simples, sirve para clasificar textos en función de la connotación positiva o negativa. Generalmente, el análisis de sentimiento clasifica las expresiones del texto en dos tipos: En hechos, que se basa en expresiones objetivas sobre los eventos y sus atributos, por ejemplo, ‘’Compré un iPhone ayer’‘; y en opiniones, que son expresiones subjetivas de sentimientos, actitudes, emociones, o apreciaciones hacia los eventos y sus atributos, por ejemplo,’‘Realmente amo esta nueva cámara’’ [2].
Para ejemplificar el análisis de sentimientos, vamos a abordar diversos Tweets sobre el COVID-19, ya que, sin duda, la era coronavirus trajo consigo cambios a nivel mundial, lo que pudo provocar un impacto emocional tanto en las personas jóvenes, como en las adultas. Para ello, vamos a tomar datos de la página web Kaggle y por medio del paquete “tidytext” del software R (el cual proporciona acceso a varios léxicos de sentimientos basados en unigramas del idioma inglés) clasificarlos en los diferentes sentimientos. Entre los principales léxicos tenemos los siguientes:
LÉXICO AFINN
Esté léxico es un listado de 1.468 palabras incluidas algunas frases, el cual se fue actualizando en el transcurso del tiempo utilizando la plataforma de Twitter para determinar en qué contextos se utilizan los diferentes términos; asimismo, se excluyeron algunas palabras para evitar ambigüedades. Por tanto, la versión más reciente cuenta con 2.477 palabras en su totalidad, incluyendo 15 frases [3]. Su autor Finn ˚Arup Nielsen, asignó las palabras con un puntaje que va desde -5 a 5, estableciendo los puntajes negativos cómo sentimientos desfavorables, y los puntajes positivos cómo sentimientos favorables. Por ejemplo, para los tweets sobre COVID-19 obtuvimos el siguiente gráfico:
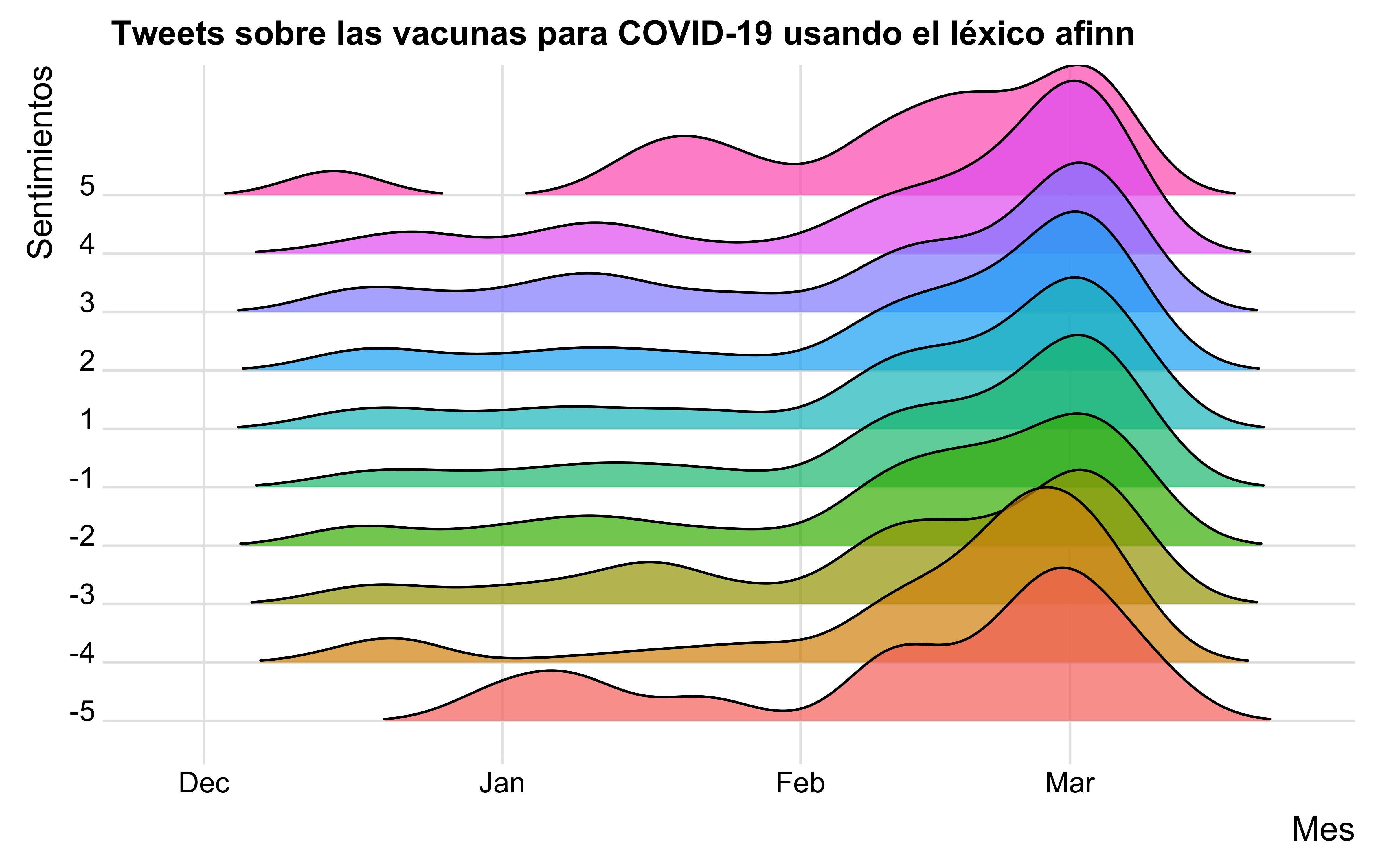
Cómo se puede observar en la gráfica, en el mes de enero los sentimientos eran totalmente desfavorables con un puntaje de -5. Por el contrario, en el mes de febrero comienzan a verse más comentarios favorables; sin embargo es hasta el mes de marzo que la vacunación para el COVID-19 toma mayor fuerza, se denota que los sentimientos de las personas frente a este tema son subjetivos y muy diferentes, existen personas que les pareció de forma muy favorable, cómo a otras personas que lo tomaron absolutamente desfavorable.
LÉXICO BING
Esté léxico es un resumen de opiniones basado en aspectos, que contiene 6.787 palabras las cuales se clasifican de manera binaria, ya sea positivo o negativo. Para definir la opinión del texto, se realizan tres subtareas: Primero, al conjunto de palabras adjetivas que normalmente utilizamos para expresar opiniones, las identifican utilizando un método de procesamiento del lenguaje. En segundo lugar, para cada palabra de opinión determinan su orientación semántica, en la cual se propone una técnica para realizar esta tarea usando la base de datos de WordNet. Finalmente, decidimos la orientación de la opinión en cada oración, sin embargo, un algoritmo eficaz también sirve para este propósito [4]. En el siguiente gráfico , podemos visualizar la funcionalidad del léxico Bing en los tweets de covid-19:
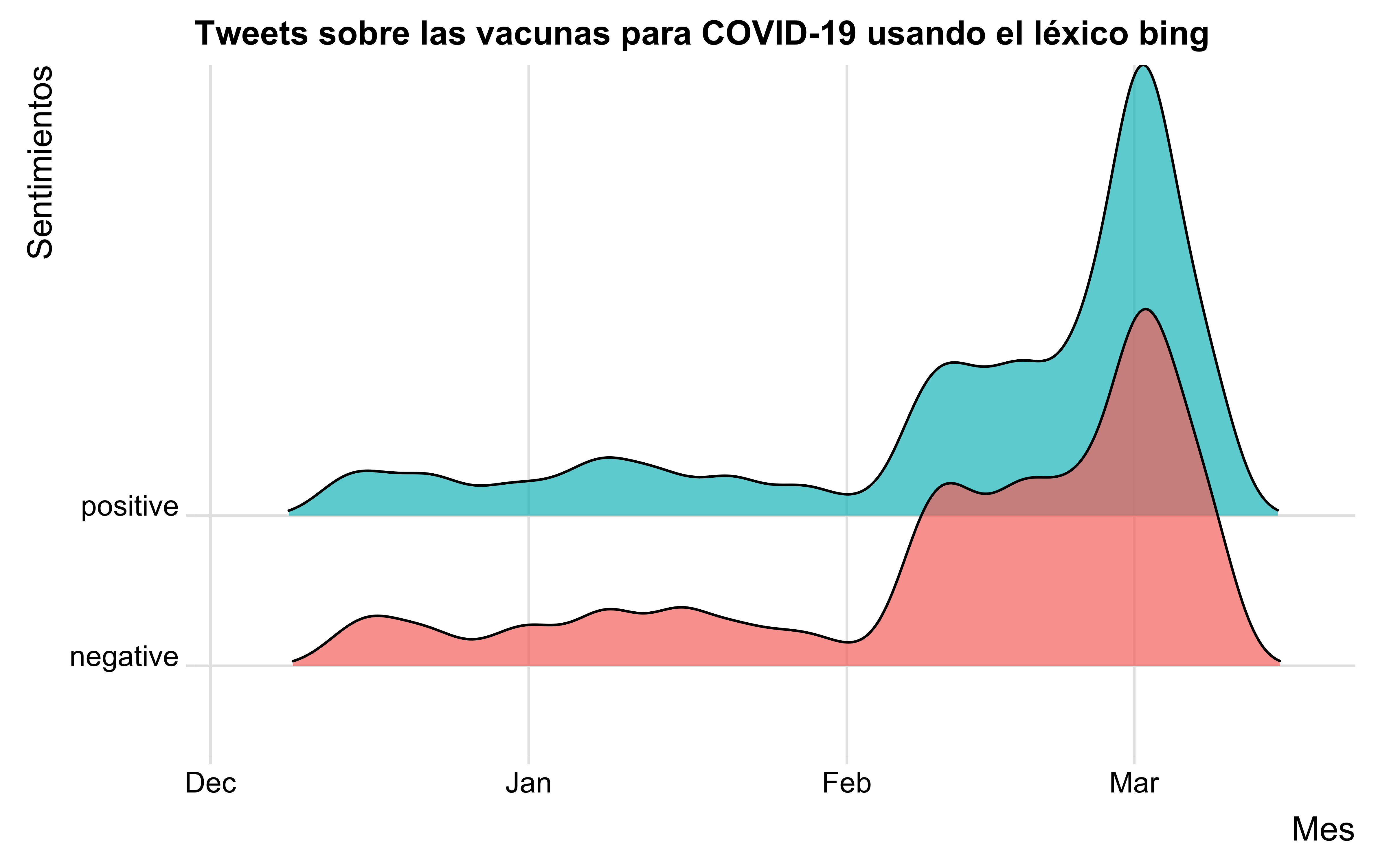
Cómo se muestra en la gráfica, en los meses de enero y febrero el tema del COVID-19 no tenía tanta relevancia cómo en el mes de marzo, donde podemos ver que las personas opinaban en gran medida sobre el virus mediante la plataforma. Además, podemos observar que las personas tenían sentimientos tanto positivos cómo negativos en relación a la vacunación.
LÉXICO NRC
Esté léxico impactó el trabajo de análisis de sentimiento, ya que fue el primer léxico y el más extenso de la asociación palabra - emoción. Contiene 14.182 palabras asociadas a ocho emociones básicas: ira, miedo, anticipación, confianza, sorpresa, tristeza, alegría y disgusto, categorizando las palabras según su connotación. A diferencia de los anteriores léxicos, NRC incluyó un conjunto más amplio de palabras que están asociadas o que connotan una emoción. Además, se realizó un control de calidad para garantizar las anotaciones adecuadas [5]. El léxico no solo se ha utilizado para análisis de sentimientos, sino también, para la detección de lenguaje abusivo, identificación de rasgos de personalidad, detección de posturas, entre otros. Es especialmente útil en entornos sin supervisión, y cuando los datos son limitados o no disponibles [5]. En el gráfico a seguir, damos cuenta de lo completo que es este léxico:
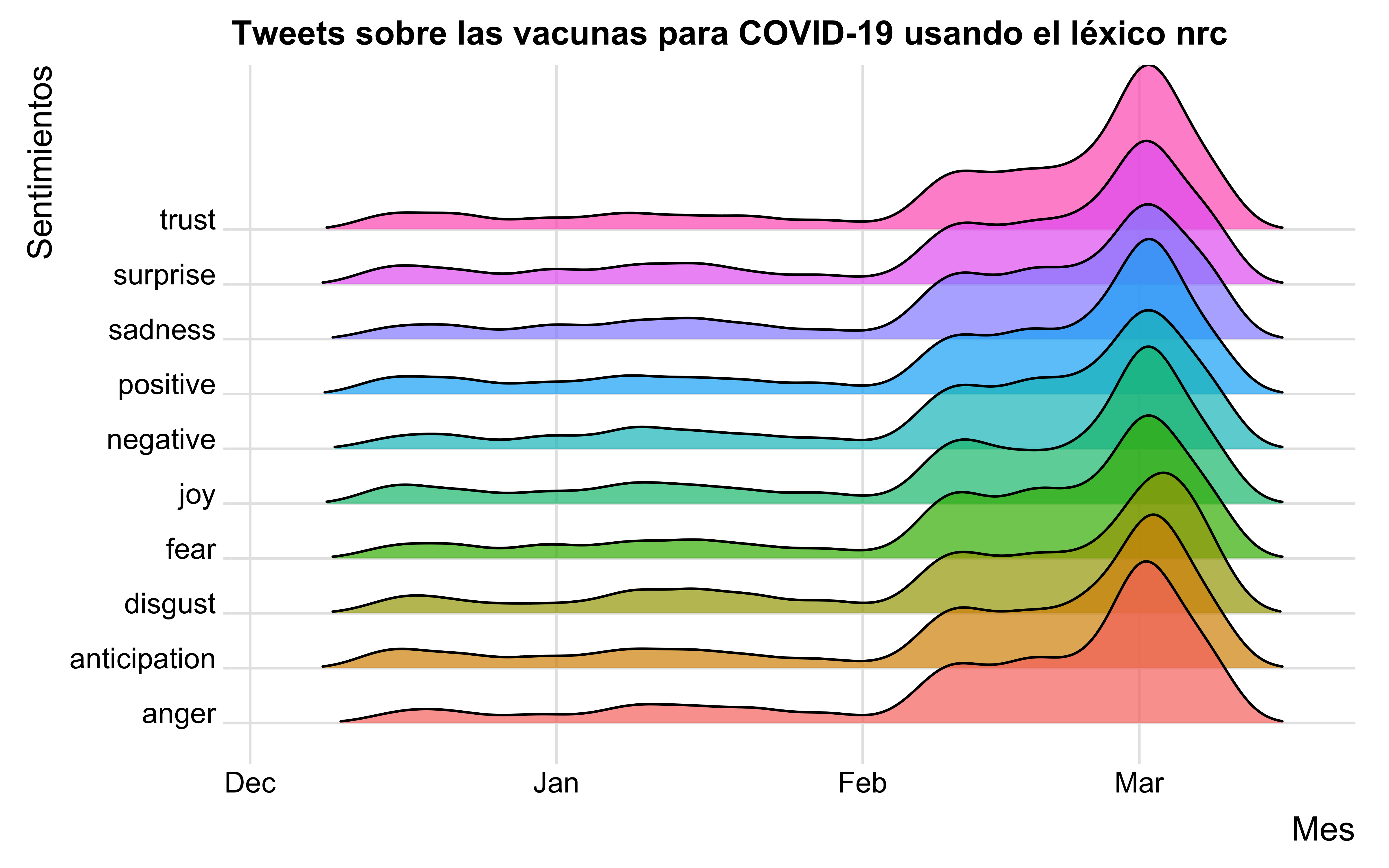
La gráfica nos muestra el impacto emocional que tuvo el coronavirus en la opinión de las personas, allí podemos detallar emociones que se vieron envueltas frente a esta situación, ya que visualizamos una mezcla de sentimientos, desde personas expresando confianza, cómo también personas expresando enojo. Es claro que en el mes de marzo se vuelve un tema de suma importancia la vacunación, ya que hay una gran cantidad de personas opinando, a diferencia de los meses anteriores.
Es importante recordar que el texto con varios párrafos generalmente puede tener sentimientos positivos y negativos, teniendo em media un sentimiento neutral, mientras que un texto corto del tamaño de una oración o de un párrafo, suele funcionar mejor. Los léxicos ya expuestos, se han desarrollado para que puedan ser utilizados en diversos contextos, pero en este caso, las funciones utilizadas nos permitieron obtener léxicos de sentimientos específicos con las medidas adecuadas para cada uno. En este post presentamos una metodología del análisis de texto, el cual nos ofrece información relevante sobre las opiniones y emociones de las personas frente un tema determinado. En este modelo de análisis de sentimiento detallamos tres diferentes léxicos, que nos ayudaron a analizar unos datos relacionados al COVID-19: el léxico AFINN nos ayudó a puntuar que tan favorables o desfavorables eran los sentimientos; el léxico BING siendo el más concreto respecto a la connotación de las opiniones; y el léxico NRC que nos muestra un resultado más completo en cuanto a la emoción concreta. Por tanto, podemos inferir que la opinión de las personas frente al coronavirus es un tema realmente subjetivo. De igual manera, este tipo de análisis lo podemos usar para cualquier otro contexto, dependiendo de los intereses del analista convendrá utilizar más una clase de léxico que otro.
Referencias
[1] Moreno, A., & Redondo, T. (2016). Text Analytics: the convergence of Big Data and Artificial Intelligence. IJIMAI, 3(6), 57-64.
[2] Luo, Tiejian & Chen, Su & Xu, Guandong & Zhou, Jia. (2013). Sentiment Analysis. 10.1007/978-1-4614-7202-5_4.
[3] Nielsen, F. Å. (2011). A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. arXiv preprint arXiv:1103.2903.
[4] Liu, B. (2020). Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge university press.
[5] Mohammad, S. M., & Turney, P. D. (2013). Crowdsourcing a word–emotion association lexicon. Computational intelligence, 29(3), 436-465.
Traducciones
Ver también
- Analizar datos de Twitter a través de R y AnalyStats-App
- Segmentación de clientes: análisis de cluster usando el algoritmo partitioning around medoids (PAM)
- Análisis de datos: Latent Dirichlet Allocation (LDA) Aplicada en Textos Periodísticos
- Un estudio al precio de arrendamiento en Medellin por medio un modelo de arbol de regresion
- Google Form: Importando datos en R y publicando resultados en AnalyStats-App