A segmentação de clientes, ou segmentação de mercado, é o processo de dividir uma base de clientes em subgrupos homogêneos dentro de um mercado heterogêneo, dirigido a ações de marketing. Esse agrupamento permite às empresas compreender seus clientes e direcionar a tomada de decisões para grupos bem definidos, atendendo às necessidades específicas de cada subgrupo. É possível, por exemplo, identificar os grupos de clientes mais lucrativos, permitindo que as organizações concentrem-se em mantê-los.
A análise de RFM (Recency-Frequency-Monetary ou Recência-Frequência-Monetária) é uma técnica amplamente utilizada na seleção de clientes significativos. Neste processo, são selecionados os clientes mais recentes (R), os mais frequentes (F) e o valor gasto (M) por eles com as empresas. Mais especificamente:
R: Tempo desde a última compra. É um importante preditor, pois um cliente que comprou há pouco tempo tem mais chance de voltar a comprar do que aquele que comprou há muito tempo, além de apresentar uma probabilidade maior de responder a promoções.
F: Quantidade de compras realizadas por um cliente em um intervalo de tempo. Se um cliente compra frequentemente, espera-se que ele volte a comprar.
M: Quantia gasta com a empresa em um intervalo de tempo. Aqueles clientes que gastaram muito têm mais valor para a organização em comparação com aqueles que gastaram menos.
Na análise RFM há diferentes tipos de segmentação. Neste texto, sugerimos onze segmentos já apresentados na literatura. Entretanto, a determinação destes deve estar de acordo com a realidade de cada empresa. A tabela abaixo apresenta a descrição de cada segmento. A terminologia aqui utilizada é uma tradução livre do inglês.
| Segmentos | Descrição | R | F | M |
|---|---|---|---|---|
| Campeões | Compraram recentemente, compram com frequência e gastam muito | 4-5 | 4-5 | 4-5 |
| Clientes fiéis | Gastam muito e respondem a promoções | 2-5 | 3-5 | 3-5 |
| Potencialmente fiéis | Compraram recentemente, mais de uma vez e gastaram uma boa quantia | 3-5 | 1-3 | 1-3 |
| Novos clientes | Compraram recentemente, mas não compram com frequência | 4-5 | <=1 | <=1 |
| Promissores | Compraram recentemente, mas não gastaram muito | 3-4 | <=1 | <=1 |
| Precisam de atenção | Recência, frequência e valor monetário acima da média | 2-3 | 2-3 | 2-3 |
| Quase em risco | Recência, frequência e valor monetário abaixo da média | 2-3 | <=2 | <=2 |
| De risco | Gastaram muito, compraram muitas vezes, mas há muito tempo | <=2 | 2-5 | 2-5 |
| Não pode perdê-los | Compraram muito e com frequência, mas há muito tempo | <=1 | 4-5 | 4-5 |
| Hibernando | Compraram pouco, com baixa frequência e há muito tempo | 1-2 | 1-2 | 1-2 |
| Perdidos | Recência, frequência e valores monetários baixos | <=2 | <=2 | <=2 |
Implementação de RFM em Knime
Na bibliografia há diversas aplicações de RFM utilizando diferentes sofwtare, a maioria delas feitas em R ou Python. Já apresentado no post anterior, o Knime é uma plataforma de código aberto para mineração e análise de dados. Propomos aqui o uso do Knime para desenvolver uma análise RFM no banco de dados E-Commerce Data, disponibilizado pela UCI Machine Learning Repository. O conjunto de dados contém as transações ocorridas entre 01/12/2010 e 09/12/2011 em uma loja de varejo on-line com sede e registro no Reino Unido.
Para o desenvolvimento deste estudo, utilizamos apenas algumas das variáveis presentes na base dados:
| Variável | Descrição | Classificação da variável |
|---|---|---|
| ID-Cliente | Um número de 5 dígitos atribuído a cada cliente | Nominal |
| Data da fatura | Dia e a hora em que cada transação foi gerada | Numérica |
| Quantidade | As quantidades de cada produto (item) por transação | Numérica |
| Preço unitário | Preço do produto por unidade em libras esterlinas | Numérica |
A implementação de RFM em Knime é feita em quatro etapas:
- Leitura dos dados: Utilize um nó para ler os dados conforme o formato no qual estejam armazenados.
- Depuração dos dados: Utilize nós que permitam limpar os dados. Por exemplo, tirar NAs e deixar as datas nos formatos adequados.
- Cálculo das variavéis RFM: Com os dados prontos para a análise, calcule para cada cliente as variáveis de Recência, Frequência e Valor Monetário.
- Cálculo do Score e definição dos segmentos: O score atribuído a cada cliente é dado de acordo com o quintil ao qual ele pertence. Por exemplo, suponha que um cliente pertença aos 20% que compraram mais recentemente, aos 20% que menos compraram e aos 20% que menos gastaram. Isto corresponde ao 5º quintil da recência, 1º quintil da frequência e ao 1º quintil do monetário. Dessa forma, a RFM desse cliente seria 511 e estaria definido no segmento novo cliente.
Abaixo apresentamos como seria um workflow para a realização de uma análise RFM em Knime.
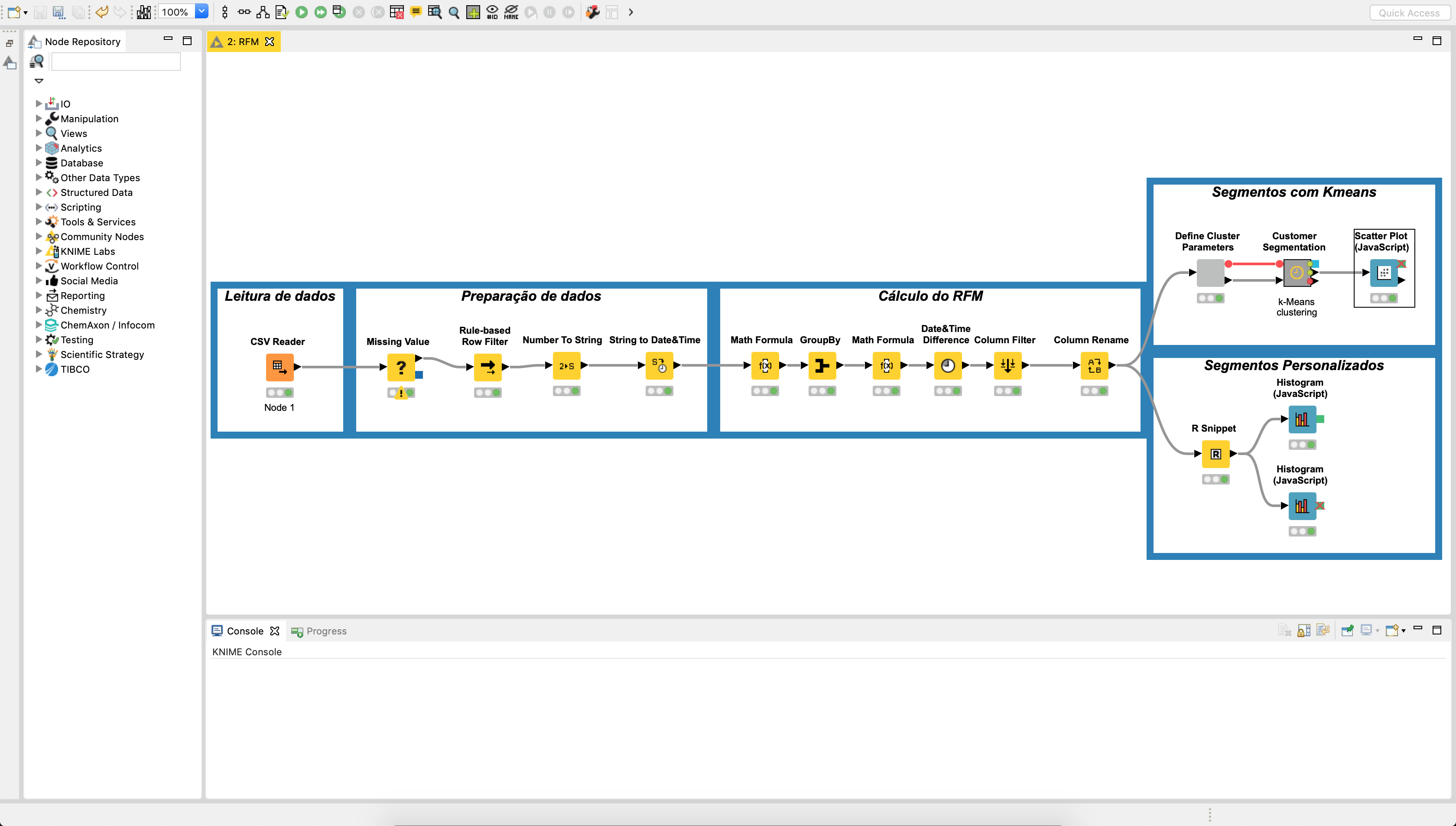
O resultado para alguns clientes é exibido na tabela abaixo:
| ID Cliente | Recência | Frequência | Valor Monetário | Score Recência | Score Frequência | Score Valor Monetário | RFM | Segmentos |
|---|---|---|---|---|---|---|---|---|
| 12346 | 348 | 1 | 77183.6000 | 1 | 1 | 5 | 115 | Perdidos |
| 12347 | 25 | 7 | 615.7143 | 5 | 5 | 5 | 555 | Campeones |
| 12348 | 98 | 4 | 449.3100 | 2 | 4 | 4 | 244 | Clientes fieles |
| 12349 | 41 | 1 | 1757.5500 | 4 | 1 | 5 | 415 | Perdidos |
| 12350 | 333 | 1 | 334.4000 | 1 | 1 | 3 | 113 | Perdidos |
| 12352 | 59 | 8 | 313.2550 | 3 | 5 | 3 | 353 | Clientes fieles |
Com os clientes já classificados, podemos inicialmente analisar a quantidade deles em cada segmento e as proporções que representam dentro do banco de dados. Posteriormente, analisar as distribuições da Recência, Frequência e Valor Monetário.
Pelos boxplots observamos que a distribuição do Valor Monetário tem uma natureza mais simétrica e dispersa do que aquelas correspondentes à Recência e à Frequência. Em termos de assimetria, a da variável Frequência é maior do que a da Recência, ambas positivas.Nosso interesse agora é avaliar conjuntamente as três variáveis dentro de cada segmento. Para tal, esboçamos os gráficos para cada grupo, em que o diâmetro do círculo é proporcional ao valor monetário por cliente.
Como já esperado, os segmentos Hibernando, De risco, Quase em risco e Precisam de atenção, apresentam frequências muito baixas (compraram no máximo quinze vezes). Porém, seria interessante uma investigação no grupo de clientes perdidos, pois observamos clientes que compraram muitas vezes e recemente, mas que gastaram em média muito pouco. Um exame mais minucioso do perfil desses clientes poderia ser últil em ações de marketing para recuperá-los.
Os segmentos Clientes fiéis e Campeões apresentaram frequências semelhantes, assim como valor monetário, exceto pelo último grupo, que tem um cliente com uma frequência maior.
Outra alternativa é aplicar sobre os atributos do RFM um algoritmo de cluster baseado em distâncias. Um exemplo seria usar o algoritmo K-means, como é proposto por [1]. Este procedimento poderia ajudar a entender melhor as regras de classificação e portanto, ter maior entendimento de cada segmento.
Observe que o algoritmo K-means agrupa os clientes dando maior importância à Recência. Porém, seria interessante uma investigação no cluster número 1, pois observamos que o algoritmo detectou que, além de ter uma Recência baixa, tem uma Frequência alta.
Referências
[2] Hebbali A, RFM - Customer Level Data, 2019.
[3] M Hendra Herviawan, Customer Segmentation using RFM Analysis (R), 2019.
Veia Também
- Business Analytics no Knime
- Um estudo do preço de aluguel em Medellín por meio de um modelo de árvore de regressão
- Google Form: Importando dados em R e publicando resultados em AnalyStats-App
- Analisar dados do Youtube por meio do R e AnalyStats-App
- Analisar dados do Twitter por meio do R e AnalyStats-App