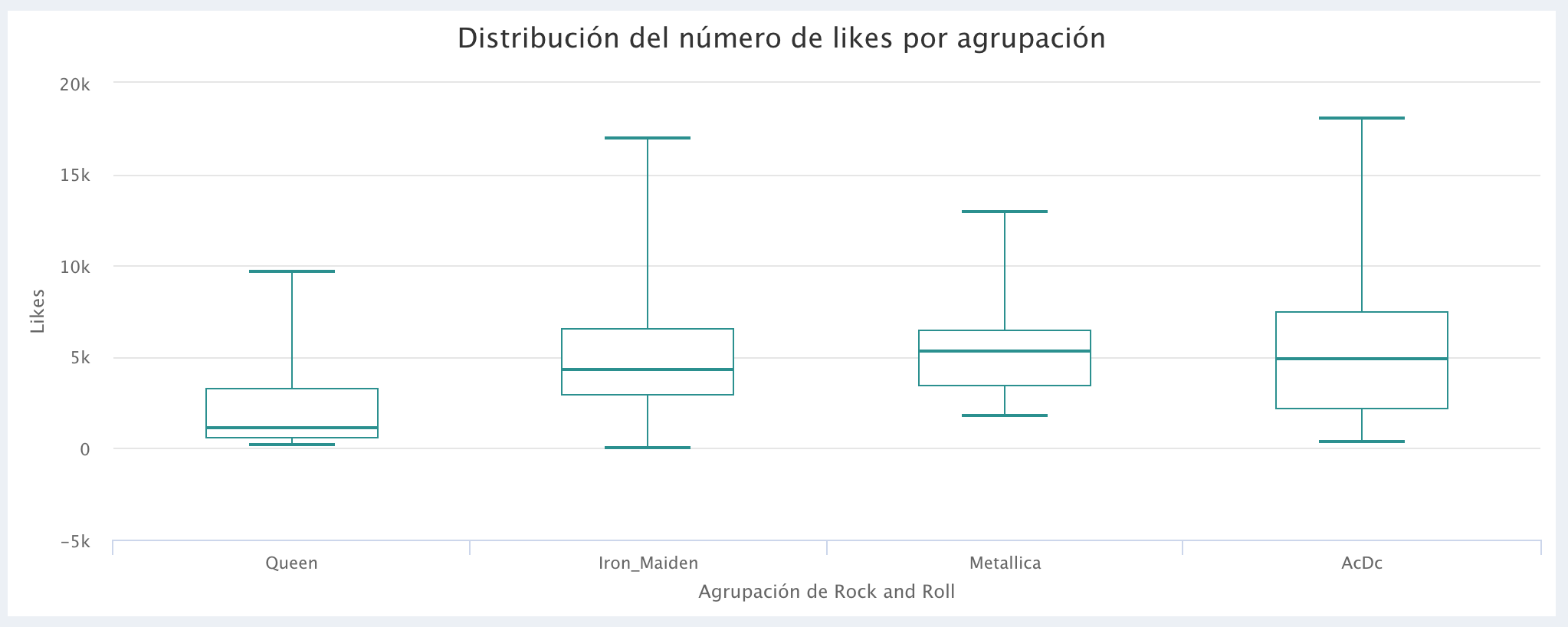
Comparação do número de Likes:
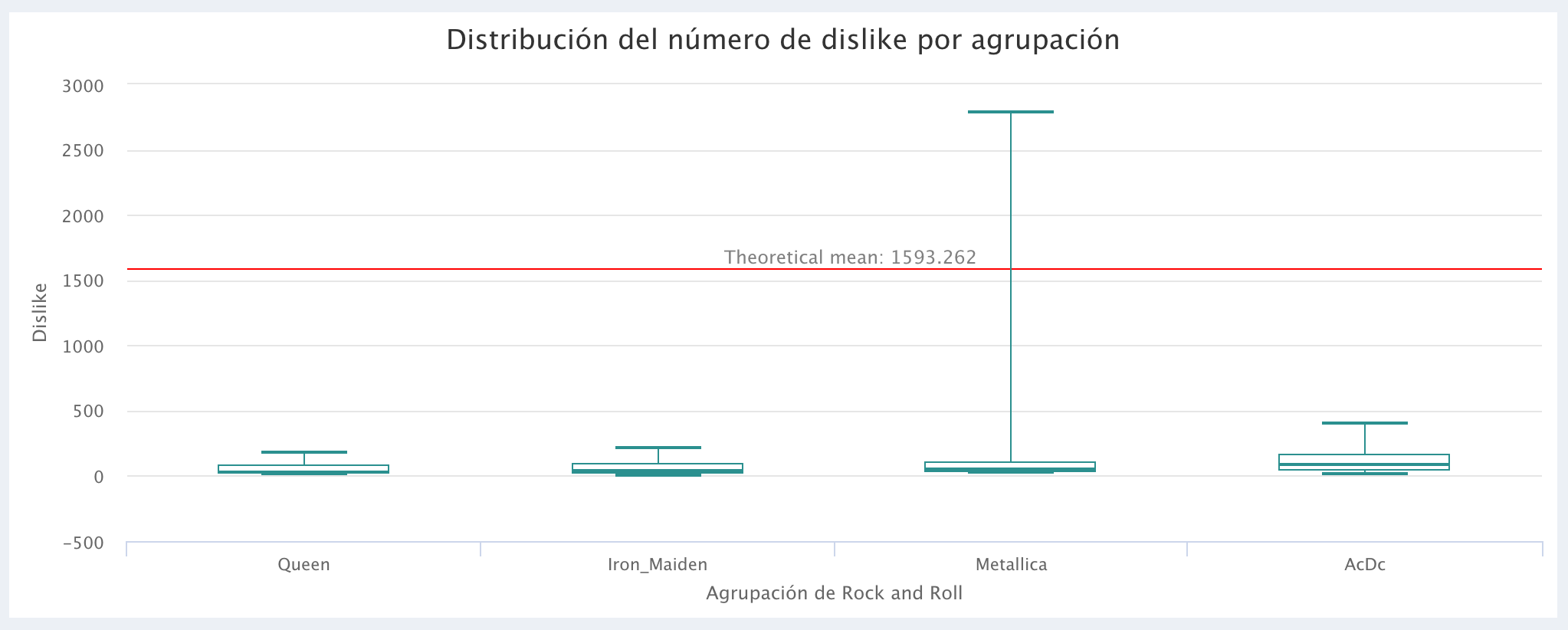
Comparação do número de Dislikes:
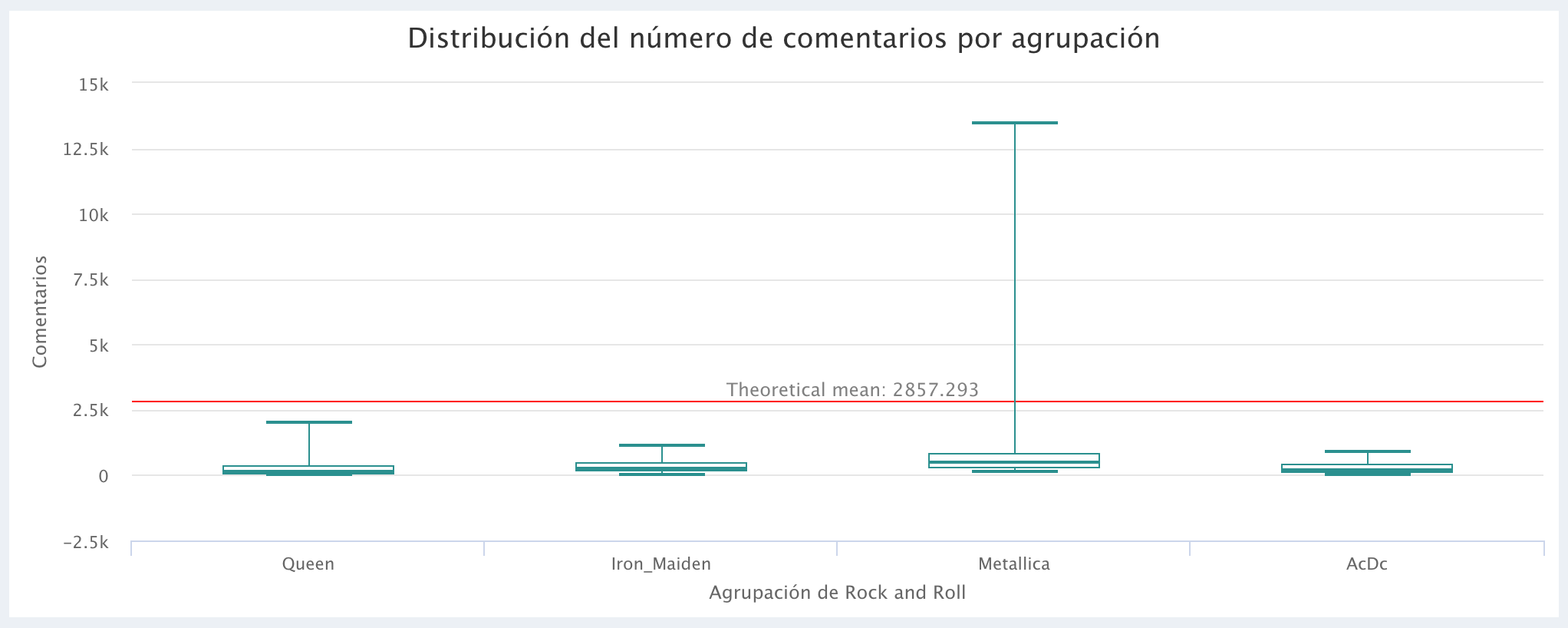
Comparação do número de Comentários:
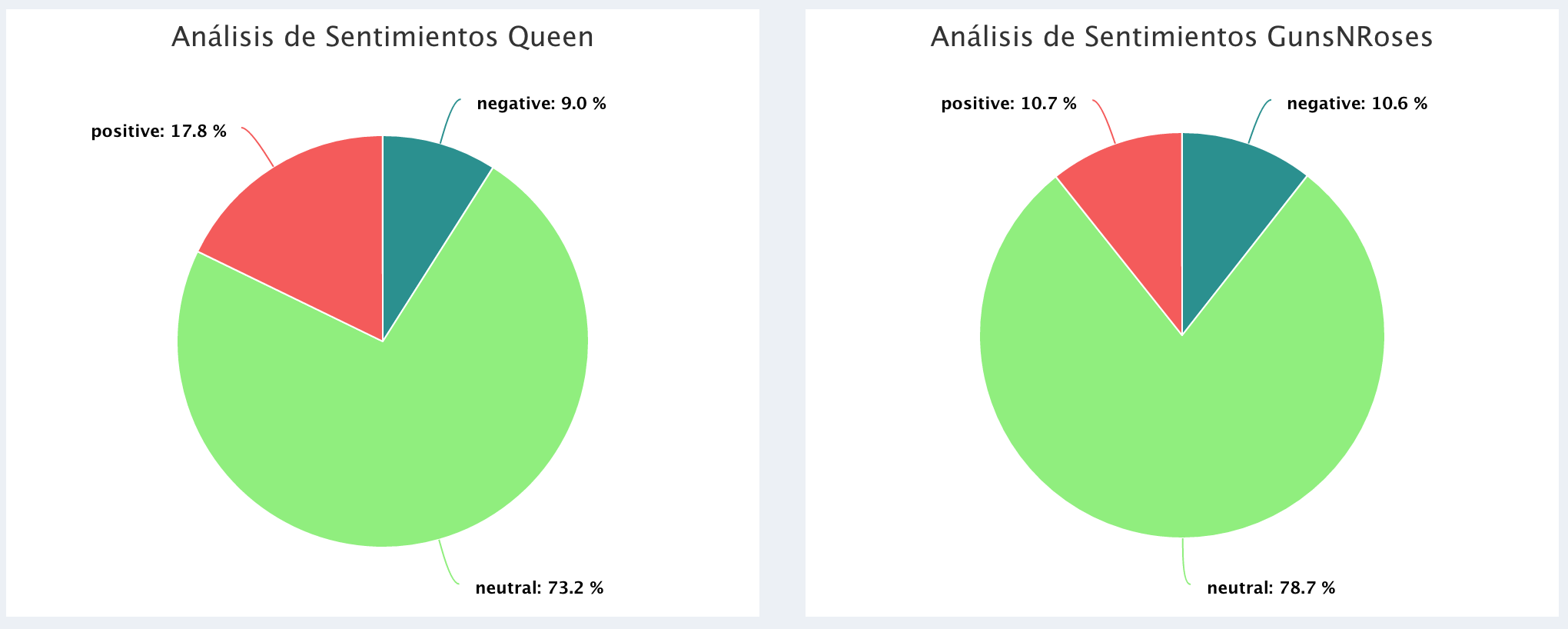
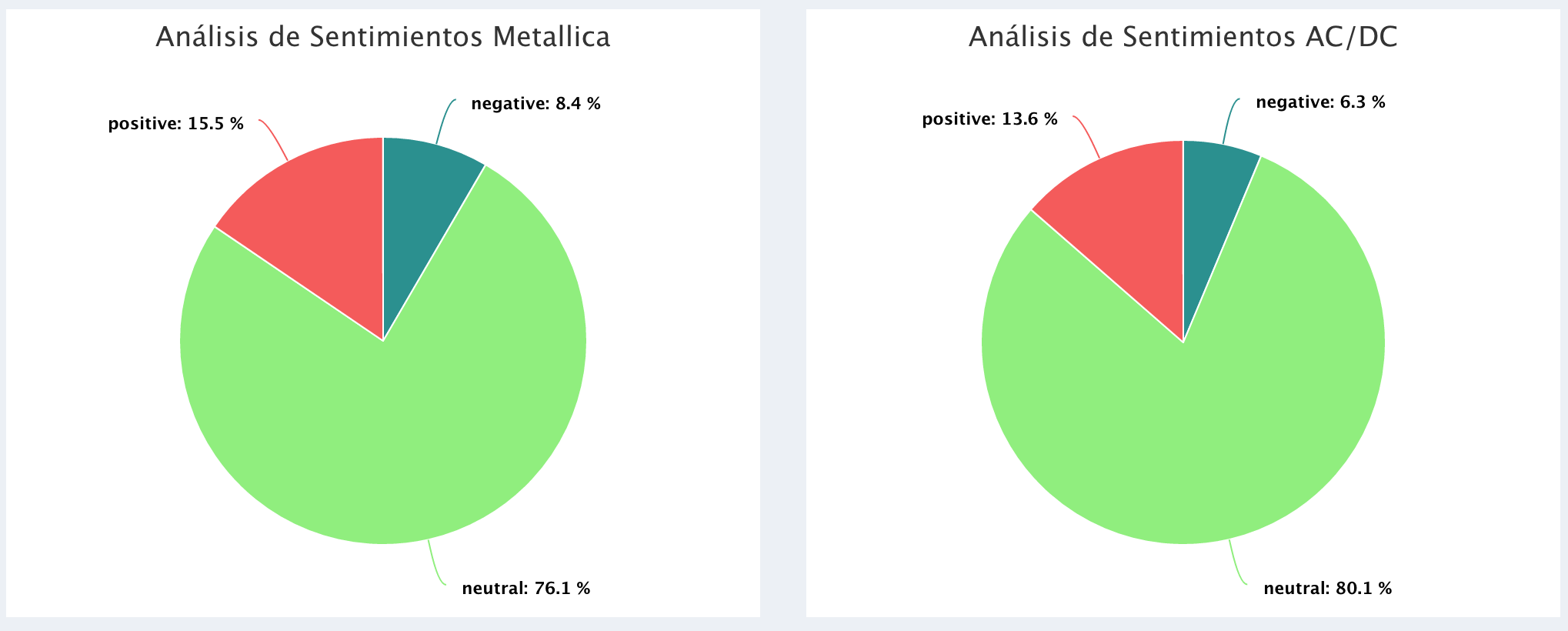
Polaridade nos comentários dos vídeos:
O Youtube é uma das principais plataformas de divulgação atual, tanto para pessoas anônimas quanto para artistas já consagrados. Dessa maneira, ele se tornou uma excelente base de dados, utilizados para diferentes tipos de análises, como relações entre diferentes artistas. Analisar seus canais usando a API pública do Youtube e o pacote tuber do R é relativamente “simples”, basta ter uma conta do google e registrar uma app para obter um “ID de cliente” y um “Secret ID”. Como ilustração, vamos baixar dados das bandas Iron Maiden, Ac/Dc, GunsNRoses, Queen e Metallica, e realizar uma comparação de suas principais estatísticas (Views, Likes, Unlikes e Comments).
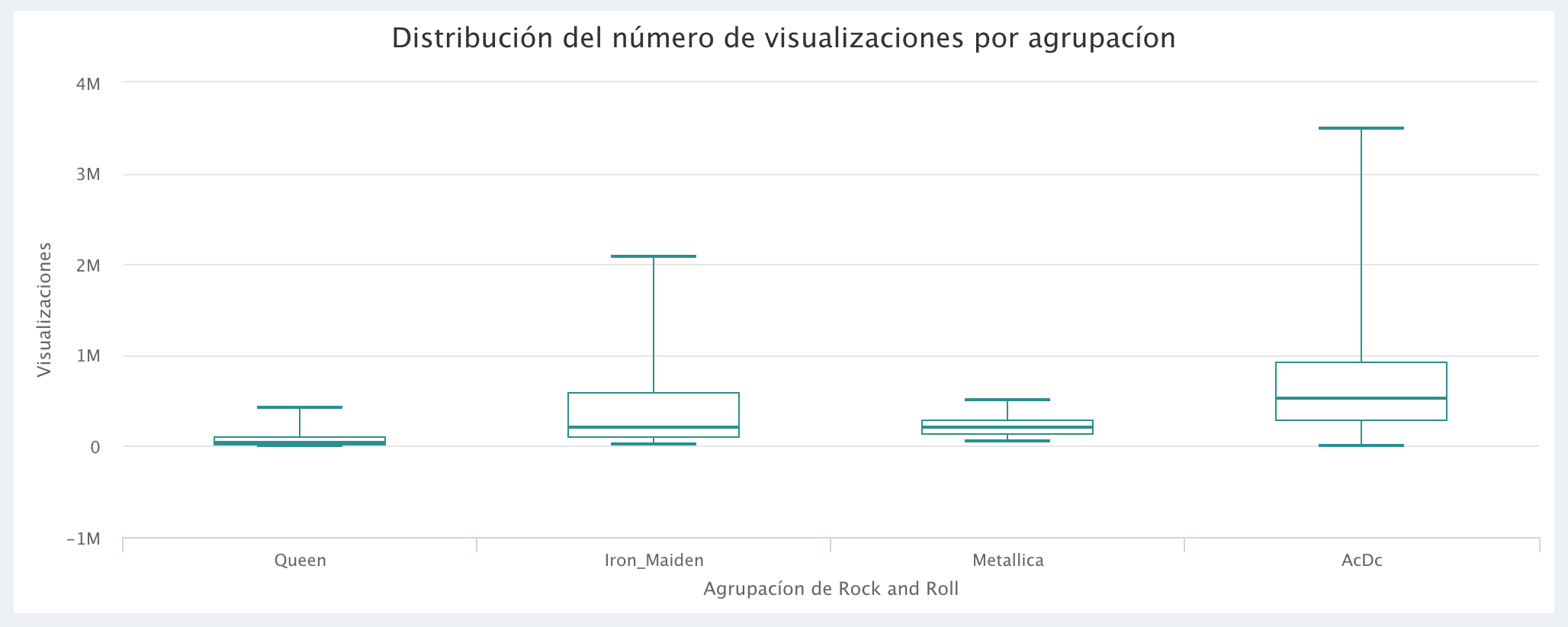
Comparação do número de Visualizações:
Comparação do número de Likes:
Comparação do número de Dislikes:
Comparação do número de Comentários:
Polaridade nos comentários dos vídeos:
A banda GunsNRoses apresentou uma maior varialbilidade em suas estatísticas em comparação aos demais grupos, dificultando a distinção entre eles. Por essa razão, não foi adicionada à análise gráfica. Para obter uma melhor visualização, os outliers não foram incluídos nos gráficos. Vale ressaltar que o objetivo deste post é somente mostrar como extrair dados do YouTube e visualizá-los no AnalyStats-App, de forma que numa análise estatística adequada, isso não necessitaria ser feito.
O código no R é:
#devtools::install_github("soodoku/tuber", build_vignettes)
library("tuber")
library("data.table")
library("httr")
library("tm")
library("sentiment")
library("dplyr")
library('RCurl')
library("stringr")
###### Autenticação ######
google <- oauth_endpoint(NULL, "auth", "token", base_url = "https://accounts.google.com/o/oauth2")
myapp <- oauth_app("google", "ID de cliente", secret = "SecretId")
cred <- oauth2.0_token(google, myapp, scope = "https://www.googleapis.com/auth/yt-analytics.readonly")
###### Baixa Dados ######
### Iron Maiden ###
# Informação do Canal:
a <- list_channel_resources(filter = c(channel_id = "UCaisXKBdNOYqGr2qOXCLchQ"), part="contentDetails")
# Id da lista de videos:
playlist_id <- a$items[[1]]$contentDetails$relatedPlaylists$uploads
# Baixada dos videos na lista:
vids <- get_playlist_items(filter= c(playlist_id=playlist_id))
# Ids dos Videos:
mytest <- sapply(vids$items, "[", "contentDetails")
# Numero de videos na lista
n <- length(mytest)
#Estatísticas dos videos
statistics <- data.frame(rbindlist(sapply(1:n,function(x) data.frame(get_stats(mytest[x]$contentDetails$videoId))),fill=TRUE))
#Informação adicional dos videos
details <- sapply(1:n,function(x) get_video_details(mytest[x]$contentDetails$videoId))
#Passando para data.frame e passando para numeric as colunas que são factor
nombre <- colnames(statistics)
statistics[,2:6] <- sapply(statistics[,2:6],function(x)as.numeric(as.character(x)))
colnames(statistics) <- nombre
statistics[is.na(statistics)]<-0
#Adicionando informação
for( i in 1:n){
statistics$title[i] <-details[[i]]$title
statistics$publishedAt[i] <-details[[i]]$publishedAt
statistics$channelId[i] <-details[[i]]$channelId
statistics$channelTitle[i] <-details[[i]]$channelTitle
statistics$defaultAudioLanguage[i] <-ifelse(is.null(details[[i]]$defaultAudioLanguage),"NA",details[[i]]$defaultAudioLanguage)
}
### Análise de sentimientos ###
#Traer os comentarios dos videos:
comments <- lapply(1:n,function(x) get_comment_threads(c(video_id=mytest[x]$contentDetails$videoId),text_format = "plainText"))
comments <- as.data.frame(rbindlist(comments, fill=TRUE))
comments <-comments[,c(5,6,11)]
comments$textDisplay<-sapply(1:length(comments[,1]),function(x)iconv(comments$textDisplay[x], to="UTF-8", sub="byte"))
sentiments<-lapply(comments$textDisplay,function(x)tryCatch(sentiment(x),error=function(e)NULL))
sentiments <- as.data.frame(rbindlist(sentiments, fill=TRUE))
#Cálculo da polaridad:
sentiments <- sentiment(comments$textDisplay)
sentimentsPolarity<-as.data.frame(round(prop.table(table(sentiments$polarity))*100,1))
### Linea do tiempo ###
sentiments$score <- 0
sentiments$score[sentiments$polarity == "positive"] <- 1
sentiments$score[sentiments$polarity == "negative"] <- -1
sentiments$score[sentiments$polarity == "neutral"] <- 0
sentiments$date <- as.IDate(comments$publishedAt)
result <- aggregate(score ~ date, data = sentiments, sum)
### AC/DC ###
# Informação do Canal:
b <- list_channel_resources(filter = c(channel_id = "UCmPuJ2BltKsGE2966jLgCnw"), part="contentDetails")
# Id da lista de videos:
b_playlist_id <- b$items[[1]]$contentDetails$relatedPlaylists$uploads
# Baixada dos videos na lista
b_vids <- get_playlist_items(filter= c(playlist_id=b_playlist_id))
# Ids dos Videos
b_mytest <- sapply(b_vids$items, "[", "contentDetails")
# Número de videos na lista
b_n <- length(mytest)
#Estatísticas dos videos
b_statistics <- data.frame(rbindlist(lapply(1:b_n,function(x) data.frame(get_stats(b_mytest[x]$contentDetails$videoId))),fill=TRUE))
#Informação adicional dos videos
b_details <- lapply(1:n,function(x) get_video_details(b_mytest[x]$contentDetails$videoId))
#Passando para data.frame e passando para numeric as colunas que são factor
b_nombre <- colnames(b_statistics)
b_statistics[,2:6] <- sapply(b_statistics[,2:6],function(x)as.numeric(as.character(x)))
colnames(b_statistics) <- b_nombre
b_statistics[is.na(b_statistics)]<-0
#Adicionando informação
for( i in 1:n){
b_statistics$title[i] <-b_details[[i]]$title
b_statistics$publishedAt[i] <-b_details[[i]]$publishedAt
b_statistics$channelId[i] <-b_details[[i]]$channelId
b_statistics$channelTitle[i] <-b_details[[i]]$channelTitle
b_statistics$defaultAudioLanguage[i] <-ifelse(is.null(b_details[[i]]$defaultAudioLanguage),"NA",b_details[[i]]$defaultAudioLanguage)
}
### Análise de sentimientos ###
#Traer os comentarios dos videos:
b_comments <- lapply(1:b_n,function(x) get_comment_threads(c(video_id=b_mytest[x]$contentDetails$videoId),text_format = "plainText"))
b_comments <- as.data.frame(rbindlist(b_comments, fill=TRUE))
b_comments <-b_comments[,c(5,6,11)]
b_comments$textDisplay<-sapply(1:length(b_comments[,1]),function(x)iconv(b_comments$textDisplay[x], to="UTF-8", sub="byte"))
b_sentiments<-lapply(b_comments$textDisplay,function(x)tryCatch(sentiment(x),error=function(e)NULL))
b_sentiments <- as.data.frame(rbindlist(b_sentiments, fill=TRUE))
#Cálculo da polaridad:
b_sentiments <- b_sentiments[b_sentiments$language=="en",]
b_sentimentsPolarity<-as.data.frame(round(prop.table(table(b_sentiments$polarity))*100,1))
### Linea do tiempo ###
b_sentiments$score <- 0
b_sentiments$score[b_sentiments$polarity == "positive"] <- 1
b_sentiments$score[b_sentiments$polarity == "negative"] <- -1
b_sentiments$score[b_sentiments$polarity == "neutral"] <- 0
b_sentiments$date <- as.IDate(b_comments$publishedAt)
b_result <- aggregate(score ~ date, data = b_sentiments, sum)
### GunsNRosesVEVO ###
# Informação do Canal:
d <- list_channel_resources(filter = c(channel_id = "UCJN4c_lZorb_0eyIP_tSS3A"), part="contentDetails")
# Id da lista de videos:
d_playlist_id <- d$items[[1]]$contentDetails$relatedPlaylists$uploads
# Baixada dos videos na lista
d_vids <- get_playlist_items(filter= c(playlist_id=d_playlist_id))
# Ids dos Videos
d_mytest <- sapply(d_vids$items, "[", "contentDetails")
#Estatísticas dos videos
d_statistics <- data.frame(rbindlist(lapply(1:d_n,function(x) data.frame(tryCatch(get_stats(d_mytest[x]$contentDetails$videoId),error=function(e) NULL))),fill=TRUE))
#informação adicional dos videos
d_details <- lapply(1:n,function(x) tryCatch(get_video_details(d_mytest[x]$contentDetails$videoId),error=function(e) NULL))
#passando a data.frame e passando a numeric as columnas que são factor
d_nombre <- colnames(d_statistics)
d_statistics[,2:6] <- sapply(d_statistics[,2:6],function(x)as.numeric(as.character(x)))
colnames(d_statistics) <- d_nombre
d_statistics[is.na(d_statistics)]<-0
# Numero de videos na lista
d_n<-length(d_statistics[,1])
#Adicionando Informação
for( i in 1:d_n){
d_statistics$title[i] <-d_details[[i]]$title
d_statistics$publishedAt[i] <-d_details[[i]]$publishedAt
d_statistics$channelId[i] <-d_details[[i]]$channelId
d_statistics$channelTitle[i] <-d_details[[i]]$channelTitle
d_statistics$defaultAudioLanguage[i] <-ifelse(is.null(d_details[[i]]$defaultAudioLanguage),"NA",d_details[[i]]$defaultAudioLanguage)
}
### Análise de sentimientos ###
#Traer os comentarios dos videos:
d_comments <- lapply(1:d_n,function(x) get_comment_threads(c(video_id=d_mytest[x]$contentDetails$videoId)))
d_comments <- as.data.frame(rbindlist(d_comments, fill=TRUE))
d_comments <-d_comments[,c(5,6,11)]
d_comments$textDisplay<-sapply(1:length(d_comments[,1]),function(x)iconv(d_comments$textDisplay[x], to="UTF-8", sub="byte"))
d_sentiments<-lapply(d_comments$textDisplay,function(x)tryCatch(sentiment(x),error=function(e) NULL))
d_sentiments <- as.data.frame(rbindlist(d_sentiments, fill=TRUE))
#Cálculo da polarilidad:
d_sentiments <- d_sentiments[d_sentiments$language=="en",]
d_sentimentsPolarity<-as.data.frame(round(prop.table(table(d_sentiments$polarity))*100,1))
### Linea do tiempo ###
d_sentiments$score <- 0
d_sentiments$score[d_sentiments$polarity == "positive"] <- 1
d_sentiments$score[d_sentiments$polarity == "negative"] <- -1
d_sentiments$score[d_sentiments$polarity == "neutral"] <- 0
d_sentiments$date <- as.IDate(d_comments$publishedAt)
d_result <- aggregate(score ~ date, data = d_sentiments, sum)
### Queen ###
# Informação do Canal:
e <- list_channel_resources(filter = c(channel_id = "UCiMhD4jzUqG-IgPzUmmytRQ"), part="contentDetails")
# Id da lista de videos:
e_playlist_id <- e$items[[1]]$contentDetails$relatedPlaylists$uploads
# Descarga dos videos na lista:
e_vids <- get_playlist_items(filter= c(playlist_id=e_playlist_id))
# Ids dos Videos:
e_mytest <- sapply(e_vids$items, "[", "contentDetails")
e_n<-length(e_mytest)
#Estatísticas dos videos:
e_statistics <- data.frame(rbindlist(lapply(1:e_n,function(x) data.frame(tryCatch(get_stats(e_mytest[x]$contentDetails$videoId),error=function(e) NULL))),fill=TRUE))
#Informação adicional dos videos:
e_details <- lapply(1:e_n,function(x) tryCatch(get_video_details(e_mytest[x]$contentDetails$videoId),error=function(e) NULL))
#Passando para data.frame e passando para numeric as columnas que são factor:
e_nombre <- colnames(e_statistics)
e_statistics[,2:6] <- sapply(e_statistics[,2:6],function(x)as.numeric(as.character(x)))
colnames(e_statistics) <- e_nombre
e_statistics[is.na(e_statistics)]<-0
# Numero de videos na lista:
e_n<-length(e_statistics[,1])
#Adicionando informacón:
for( i in 1:e_n){
e_statistics$title[i] <-e_details[[i]]$title
e_statistics$publishedAt[i] <-e_details[[i]]$publishedAt
e_statistics$channelId[i] <-e_details[[i]]$channelId
e_statistics$channelTitle[i] <-e_details[[i]]$channelTitle
e_statistics$defaultAudioLanguage[i] <-ifelse(is.null(e_details[[i]]$defaultAudioLanguage),"NA",e_details[[i]]$defaultAudioLanguage)
}
### Análise de sentimientos ###
#Traer os comentarios dos videos:
e_comments <- lapply(1:e_n,function(x) get_comment_threads(c(video_id=e_mytest[x]$contentDetails$videoId)))
e_comments <- as.data.frame(rbindlist(e_comments, fill=TRUE))
e_comments <-e_comments[,c(5,6,11)]
e_comments$textDisplay<-sapply(1:length(e_comments[,1]),function(x)iconv(e_comments$textDisplay[x], to="UTF-8", sub="byte"))
e_sentiments<-sapply(e_comments$textDisplay,function(x)tryCatch(sentiment(x),error=function(e)NULL))
e_sentiments <- as.data.frame(rbindlist(e_sentiments, fill=TRUE))
#Cálculo da polaridad:
e_sentiments <- e_sentiments[e_sentiments$language=="en",]
e_sentimentsPolarity<-as.data.frame(round(prop.table(table(e_sentiments$polarity))*100,1))
### Linea do tiempo ###
e_sentiments$score <- 0
e_sentiments$score[e_sentiments$polarity == "positive"] <- 1
e_sentiments$score[e_sentiments$polarity == "negative"] <- -1
e_sentiments$score[e_sentiments$polarity == "neutral"] <- 0
e_sentiments$date <- as.IDate(e_comments$publishedAt)
e_result <- aggregate(score ~ date, data = e_sentiments, sum)
### Metallica ###
# Informação do Canal:
f <- list_channel_resources(filter = c(channel_id = "UCbulh9WdLtEXiooRcYK7SWw"), part="contentDetails")
# Id da lista de videos:
f_playlist_id <- f$items[[1]]$contentDetails$relatedPlaylists$uploads
# Descarga dos videos na lista:
f_vids <- get_playlist_items(filter= c(playlist_id=f_playlist_id))
# Ids dos Videos:
f_mytest <- sapply(f_vids$items, "[", "contentDetails")
f_n<-length(f_mytest)
#Estatísticas dos videos
f_statistics <- data.frame(rbindlist(lapply(1:f_n,function(x) data.frame(tryCatch(get_stats(f_mytest[x]$contentDetails$videoId),error=function(e) NULL))),fill=TRUE))
#Informação adicional dos videos
f_details <- lapply(1:f_n,function(x) tryCatch(get_video_details(f_mytest[x]$contentDetails$videoId),error=function(e) NULL))
#passando para data.frame e passando para numeric as columnas que são factor
f_nombre <- colnames(f_statistics)
f_statistics[,2:6] <- sapply(f_statistics[,2:6],function(x)as.numeric(as.character(x)))
colnames(f_statistics) <- f_nombre
f_statistics[is.na(f_statistics)]<-0
# Numero de videos na lista
f_n<-length(f_statistics[,1])
#Adicionando Informação
for( i in 1:f_n){
f_statistics$title[i] <-f_details[[i]]$title
f_statistics$publishedAt[i] <-f_details[[i]]$publishedAt
f_statistics$channelId[i] <-f_details[[i]]$channelId
f_statistics$channelTitle[i] <-f_details[[i]]$channelTitle
f_statistics$defaultAudioLanguage[i] <-ifelse(is.null(f_details[[i]]$defaultAudioLanguage),"NA",f_details[[i]]$defaultAudioLanguage)
}
### Análise de sentimientos ###
#Traer os comentarios dos videos:
f_comments <- lapply(1:f_n,function(x) get_comment_threads(c(video_id=f_mytest[x]$contentDetails$videoId)))
f_comments <- as.data.frame(rbindlist(f_comments, fill=TRUE))
f_comments <-f_comments[,c(5,6,11)]
f_comments$textDisplay<-sapply(1:length(f_comments[,1]),function(x)iconv(f_comments$textDisplay[x], to="UTF-8", sub="byte"))
f_sentiments<-lapply(f_comments$textDisplay,function(x)tryCatch(sentiment(x),error=function(e)NULL))
f_sentiments <- as.data.frame(rbindlist(f_sentiments, fill=TRUE))
#Cálculo da polaridad:
f_sentiments <- f_sentiments[f_sentiments$language=="en",]
f_sentimentsPolarity<-as.data.frame(round(prop.table(table(f_sentiments$polarity))*100,1))
### Linea do tiempo ###
f_sentiments$score <- 0
f_sentiments$score[f_sentiments$polarity == "positive"] <- 1
f_sentiments$score[f_sentiments$polarity == "negative"] <- -1
f_sentiments$score[f_sentiments$polarity == "neutral"] <- 0
f_sentiments$date <- as.IDate(f_comments$publishedAt)
f_result <- aggregate(score ~ date, data = f_sentiments, sum)
#statistics <- data.frame(sapply(1:6,function(x) unlist(statistics[,x])))
### Outliers ###
### Iron_Maiden viewCount outliers ###
statistics_viewCount_out<- boxplot.stats(statistics$viewCount)$out
statistics_viewCount_box<- setdiff(statistics$viewCount, statistics_viewCount_out )
### AcDc viewCount outliers ###
b_statistics_viewCount_out<- boxplot.stats(b_statistics$viewCount)$out
b_statistics_viewCount_box<- setdiff(b_statistics$viewCount, b_statistics_viewCount_out )
### GunsNRoses viewCount outliers ###
d_statistics_viewCount_out<- boxplot.stats(d_statistics$viewCount)$out
d_statistics_viewCount_box<- setdiff(d_statistics$viewCount, d_statistics_viewCount_out )
### Queen viewCount outliers ###
e_statistics_viewCount_out<- boxplot.stats(e_statistics$viewCount)$out
e_statistics_viewCount_box<- setdiff(e_statistics$viewCount, e_statistics_viewCount_out )
### Metallica viewCount outliers ###
f_statistics_viewCount_out<- boxplot.stats(f_statistics$viewCount)$out
f_statistics_viewCount_box<- setdiff(f_statistics$viewCount, f_statistics_viewCount_out )
### Iron_Maiden likeCount outliers ###
statistics_likeCount_out<- boxplot.stats(statistics$likeCount)$out
statistics_likeCount_box<- setdiff(statistics$likeCount, statistics_likeCount_out )
### AcDc likeCount outliers ###
b_statistics_likeCount_out<- boxplot.stats(b_statistics$likeCount)$out
b_statistics_likeCount_box<- setdiff(b_statistics$likeCount, b_statistics_likeCount_out )
### GunsNRoses likeCount outliers ###
d_statistics_likeCount_out<- boxplot.stats(d_statistics$likeCount)$out
d_statistics_likeCount_box<- setdiff(d_statistics$likeCount, d_statistics_likeCount_out )
### Queen likeCount outliers ###
e_statistics_likeCount_out<- boxplot.stats(e_statistics$likeCount)$out
e_statistics_likeCount_box<- setdiff(e_statistics$likeCount, e_statistics_likeCount_out )
### Metallica likeCount outliers ###
f_statistics_likeCount_out<- boxplot.stats(f_statistics$likeCount)$out
f_statistics_likeCount_box<- setdiff(f_statistics$likeCount, f_statistics_likeCount_out )
### Iron_Maiden dislikeCount outliers ###
statistics_dislikeCount_out<- boxplot.stats(statistics$dislikeCount)$out
statistics_dislikeCount_box<- setdiff(statistics$dislikeCount, statistics_dislikeCount_out )
### AcDc dislikeCount outliers ###
b_statistics_dislikeCount_out<- boxplot.stats(b_statistics$dislikeCount)$out
b_statistics_dislikeCount_box<- setdiff(b_statistics$dislikeCount, b_statistics_dislikeCount_out )
### GunsNRoses dislikeCount outliers ###
d_statistics_dislikeCount_out<- boxplot.stats(d_statistics$dislikeCount)$out
d_statistics_dislikeCount_box<- setdiff(d_statistics$dislikeCount, d_statistics_dislikeCount_out )
### Queen dislikeCount outliers ###
e_statistics_dislikeCount_out<- boxplot.stats(e_statistics$dislikeCount)$out
e_statistics_dislikeCount_box<- setdiff(e_statistics$dislikeCount, e_statistics_dislikeCount_out )
### Metallica dislikeCount outliers ###
f_statistics_dislikeCount_out<- boxplot.stats(f_statistics$dislikeCount)$out
f_statistics_dislikeCount_box<- setdiff(f_statistics$dislikeCount, f_statistics_dislikeCount_out )
### Iron_Maiden commentCount outliers ###
statistics_commentCount_out<- boxplot.stats(statistics$commentCount)$out
statistics_commentCount_box<- setdiff(statistics$commentCount, statistics_commentCount_out )
### AcDc commentCount outliers ###
b_statistics_commentCount_out<- boxplot.stats(b_statistics$commentCount)$out
b_statistics_commentCount_box<- setdiff(b_statistics$commentCount, b_statistics_commentCount_out )
### GunsNRoses commentCount outliers ###
d_statistics_commentCount_out<- boxplot.stats(d_statistics$commentCount)$out
d_statistics_commentCount_box<- setdiff(d_statistics$commentCount, d_statistics_commentCount_out )
### Queen commentCount outliers ###
e_statistics_commentCount_out<- boxplot.stats(e_statistics$commentCount)$out
e_statistics_commentCount_box<- setdiff(e_statistics$commentCount, e_statistics_commentCount_out )
### Metallica commentCount outliers ###
f_statistics_commentCount_out<- boxplot.stats(f_statistics$commentCount)$out
f_statistics_commentCount_box<- setdiff(f_statistics$commentCount, f_statistics_commentCount_out )
DataToDash <- list(
# Informação para os Bloxplot#
viewCount = list(Iron_Maiden = c(min(statistics_viewCount_box), quantile(statistics_viewCount_box,c(0.25,0.50,0.75)), max(statistics_viewCount_box)),
AcDc = c(min(b_statistics_viewCount_box),quantile(b_statistics_viewCount_box,c(0.25,0.50,0.75)),max(b_statistics_viewCount_box)),
GunsNRoses = c(min(d_statistics_viewCount_box),quantile(d_statistics_viewCount_box,c(0.25,0.50,0.75)),max(d_statistics_viewCount_box)),
Queen = c(min(e_statistics_viewCount_box),quantile(e_statistics_viewCount_box,c(0.25,0.50,0.75)),max(e_statistics_viewCount_box)),
Metallica = c(min(f_statistics_viewCount_box),quantile(f_statistics_viewCount_box,c(0.25,0.50,0.75)),max(f_statistics_viewCount_box))
),
likeCount = list(Iron_Maiden = c(min(statistics_likeCount_box), quantile(statistics_likeCount_box,c(0.25,0.50,0.75)), max(statistics_likeCount_box)),
AcDc = c(min(b_statistics_likeCount_box),quantile(b_statistics_likeCount_box,c(0.25,0.50,0.75)),max(b_statistics_likeCount_box)),
GunsNRoses = c(min(d_statistics_likeCount_box),quantile(d_statistics_likeCount_box,c(0.25,0.50,0.75)),max(d_statistics_likeCount_box)),
Queen = c(min(e_statistics_likeCount_box),quantile(e_statistics_likeCount_box,c(0.25,0.50,0.75)),max(e_statistics_likeCount_box)),
Metallica = c(min(f_statistics_likeCount_box),quantile(f_statistics_likeCount_box,c(0.25,0.50,0.75)),max(f_statistics_likeCount_box))
),
dislikeCount = list(Iron_Maiden = c(min(statistics_dislikeCount_box), quantile(statistics_dislikeCount_box,c(0.25,0.50,0.75)), max(statistics_dislikeCount_box)),
AcDc = c(min(b_statistics_dislikeCount_box),quantile(b_statistics_dislikeCount_box,c(0.25,0.50,0.75)),max(b_statistics_dislikeCount_box)),
GunsNRoses = c(min(d_statistics_dislikeCount_box),quantile(d_statistics_dislikeCount_box,c(0.25,0.50,0.75)),max(d_statistics_dislikeCount_box)),
Queen = c(min(e_statistics_dislikeCount_box),quantile(e_statistics_dislikeCount_box,c(0.25,0.50,0.75)),max(e_statistics_dislikeCount_box)),
Metallica = c(min(f_statistics$dislikeCount),quantile(f_statistics$dislikeCount,c(0.25,0.50,0.75)),max(f_statistics$dislikeCount))
),
commentCount = list(Iron_Maiden = c(min(statistics_commentCount_box), quantile(statistics_commentCount_box,c(0.25,0.50,0.75)), max(statistics_commentCount_box)),
AcDc = c(min(b_statistics_commentCount_box),quantile(b_statistics_commentCount_box,c(0.25,0.50,0.75)),max(b_statistics_commentCount_box)),
GunsNRoses = c(min(d_statistics$commentCount),quantile(d_statistics$commentCount,c(0.25,0.50,0.75)),max(d_statistics$commentCount)),
Queen = c(min(e_statistics$commentCount),quantile(e_statistics$commentCount,c(0.25,0.50,0.75)),max(e_statistics$commentCount)),
Metallica = c(min(f_statistics$commentCount),quantile(f_statistics$commentCount,c(0.25,0.50,0.75)),max(f_statistics$commentCount))
),
viewCount_out = c(lapply(1:length(statistics_viewCount_out),function(x) c(0, statistics_viewCount_out[x])),
lapply(1:length(b_statistics_viewCount_out),function(x) c(1, b_statistics_viewCount_out[x])),
lapply(1:length(d_statistics_viewCount_out),function(x) c(2, d_statistics_viewCount_out[x])),
lapply(1:length(e_statistics_viewCount_out),function(x) c(3, e_statistics_viewCount_out[x])),
lapply(1:length(f_statistics_viewCount_out),function(x) c(4, f_statistics_viewCount_out[x]))
),
# Polaridad nos Comentarios #
AC_DC = b_sentimentsPolarity,
GunsNRoses = d_sentimentsPolarity,
Queen = e_sentimentsPolarity,
Metallica = f_sentimentsPolarity
)
### Enviando os datos para app.analystats ###
### Url da aplicación ###
url<-"https://app.analystats.com/api/24421902328004610/topics/26/content/upload"
### Enviando os datos para app.analystats:
r <- POST(url, body = DataToDash, encode = "json",authenticate("User","pass"))Veja o Dash-Board completo on-line em AnalyStats => Go to Demo => YouTube DashBoard/Ver. Para ter acesso à demonstração do nosso app, escreva para [email protected].