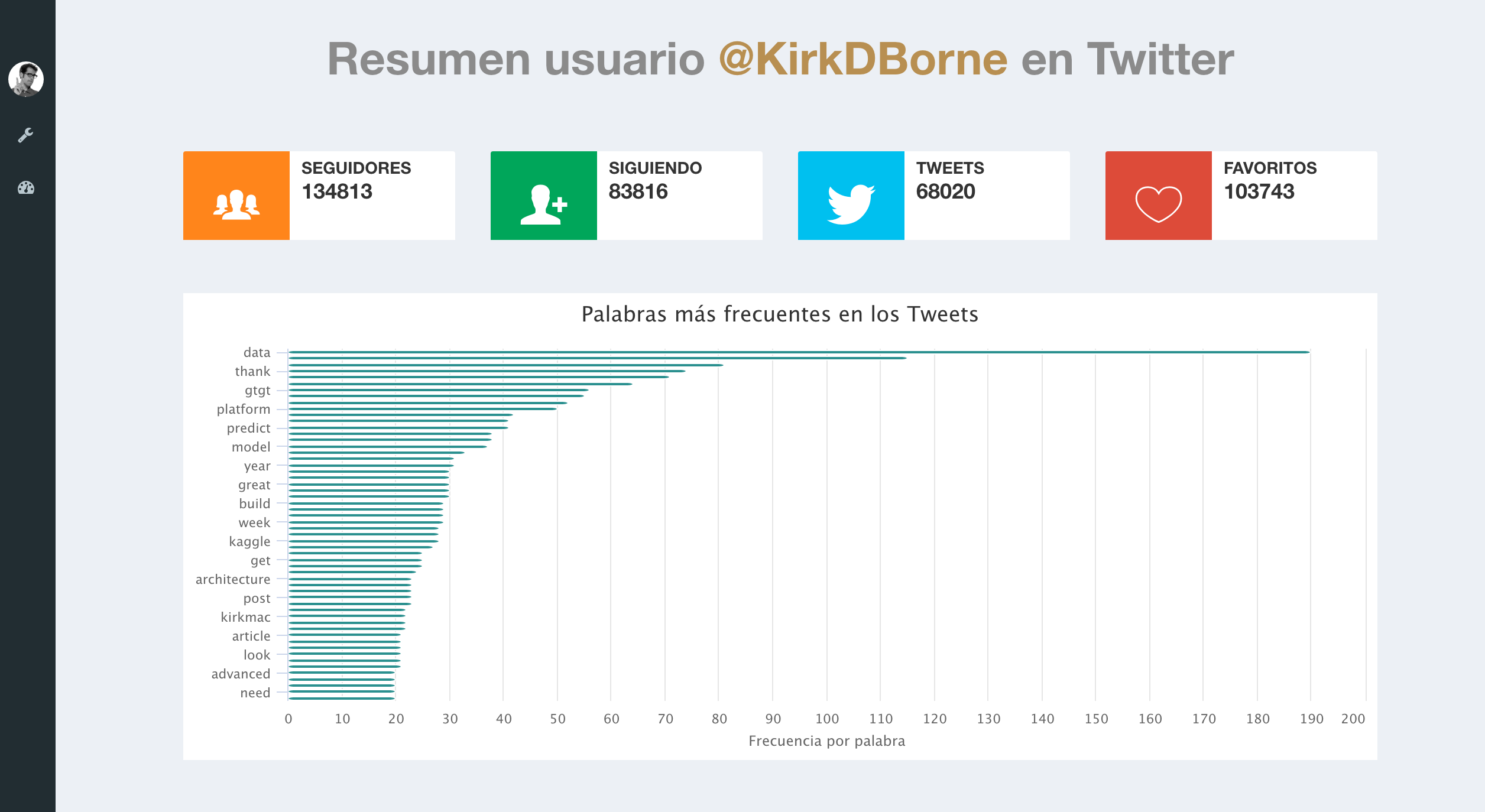
Os dados da rede social Twitter disponíveis em seu (Application Programming Interface), proporcionam uma grande quantidade de informação em tempo real. Baixar dados da API do Twitter é relativamente simples, mas necessitamos criar uma aplicação em https://dev.twitter.com (My app) e posteriormente obter um API key, API secret, token de acesso e um Token Secret de acesso (clique aqui para obter mais detalhes de como criar uma app). Neste post, utilizamos a guia desenvolvida por Yanchang Zhao Twitter Data Analysis with R para fazer um resumo da conta de Twitter do cientista de dados Kirk Borne através do R e posteriormente apresentar os resultados em um dashboard da Analystats-App. O código R é:
### Pacotes necesarios ###
library("httr")
library('ROAuth')
library('RCurl')
library("twitteR")
library("base64enc")
library("tm")
library("topicmodels")
library("data.table")
library("xts")
library("sentiment")
library("stringr")
library("SnowballC")
###### Autenticação ######
options(httr_oauth_cache=T)
reqURL <- "https://api.twitter.com/oauth/request_token"
accessURL <- "https://api.twitter.com/oauth/access_token"
authURL <- "https://api.twitter.com/oauth/authorize"
consumerKey <- "XXXXXXXXXX"
consumerSecret <- "XXXXXXXXXX"
access_token<-"XXXXXXXXXX"
access_secret<-"XXXXXXXXXX"
twitCred <- OAuthFactory$new(consumerKey=consumerKey,consumerSecret=consumerSecret,requestURL=reqURL,accessURL=accessURL,authURL=authURL)
download.file(url="https://curl.haxx.se/ca/cacert.pem", destfile="cacert.pem")
twitCred$handshake(cainfo="cacert.pem")
setup_twitter_oauth(consumerKey, consumerSecret, access_token, access_secret)
###### Baixada de twetts ######
tweets <- userTimeline("KirkDBorne", n = 3200)
###### Convierte tweets en DataFrame ######
tweets.df <- twListToDF(tweets)
### Creação do corpus e indica-se a fonte do vetor de caracteres ###
myCorpus <- Corpus(VectorSource(tweets.df$text))
### Extrae os hashtags ###
Hashtags <- function(x) str_extract_all(x, "#\\S+")
myHashtags <- tm_map(myCorpus, content_transformer(Hashtags))
### Limpa o texto ###
### Eliminan Caracteres gráficos ###
usableText=function(x) str_replace_all(x,"[^[:graph:]]", " ")
myCorpus <- tm_map(myCorpus, content_transformer(usableText))
### Pasamos todo o texto para minuscula ###
myCorpus <- tm_map(myCorpus, content_transformer(tolower))
### Elimina hashtags ###
removeHashtags <- function(x) gsub("#\\w+", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeHashtags))
### Elimina URLs ###
removeURL <- function(x) gsub("http[^[:space:]]*", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeURL))
### Elimina letras e espacios do ingles ###
removeNumPunct <- function(x) gsub("[^[:alpha:][:space:]]*", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeNumPunct))
### Elimina stopwords ###
myStopwords <- c(stopwords("en"),"s","w","d","u","e","x","b","rt","use", "see", "used", "via", "amp","also")
myCorpus <- tm_map(myCorpus, removeWords, myStopwords)
### Elimina espacios em branco extra ###
myCorpus <- tm_map(myCorpus, stripWhitespace)
### Uma copia para completar o stem posteriormente ###
myCorpusCopy <- myCorpus
### Stem das palavras ###
myCorpus <- tm_map(myCorpus, stemDocument)
stemCompletion2 <- function(x, dictionary) {
x <- unlist(strsplit(as.character(x), " "))
x <- x[x != ""]
x <- stemCompletion(x, dictionary=dictionary)
x <- paste(x, sep="", collapse=" ")
PlainTextDocument(stripWhitespace(x))
}
myCorpus <- lapply(myCorpus, stemCompletion2, dictionary=myCorpusCopy)
myCorpus <- Corpus(VectorSource(myCorpus))
### Frecuencia das palabras ###
tdm <- TermDocumentMatrix(myCorpus, control = list(wordLengths = c(1, Inf)))
term.freq <- rowSums(as.matrix(tdm))
term.freq <- subset(term.freq, term.freq >= 20)
df <- data.frame(term = names(term.freq), freq = term.freq,row.names = NULL)
df <- df[with(df, order(-freq)), ]
### Subtituir algumas palavras ###
replaceWord <- function(corpus, oldword, newword){
tm_map(corpus, content_transformer(gsub),
pattern=oldword, replacement=newword)
}
myCorpus <- replaceWord(myCorpus, "miner", "mining")
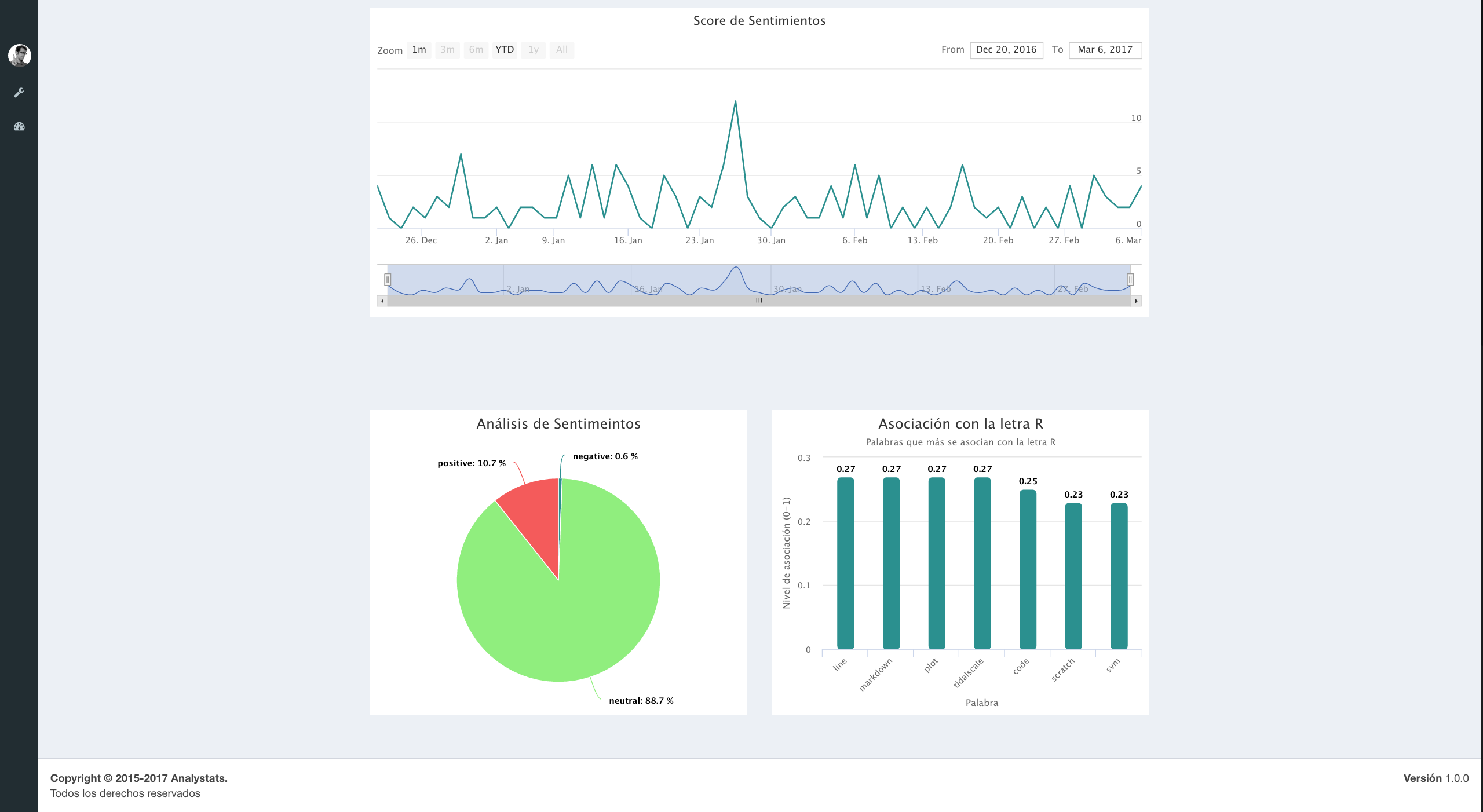
### quales palavras estão asociadas com a letra R ? ###
associatedR <- findAssocs(tdm, "r", 0.2)
myname<-attributes(associatedR$r)$names
### quales palavras estão asociadas com a palavra 'data'? ##
associatedData <- findAssocs(tdm, "data", 0.2)
### Análisis de sentimientos ###
sentiments <- sentiment(tweets.df$text)
sentimentsPolarity<-as.data.frame(round(prop.table(table(sentiments$polarity))*100,1))
### Linea do tiempo ###
sentiments$score <- 0
sentiments$score[sentiments$polarity == "positive"] <- 1
sentiments$score[sentiments$polarity == "negative"] <- -1
sentiments$score[sentiments$polarity == "neutral"] <- 0
sentiments$date <- as.IDate(tweets.df$created)
result <- aggregate(score ~ date, data = sentiments, sum)
### Informação de Usuario ###
user <- getUser("KirkDBorne")
user$toDataFrame()[,c(2,3,4,5)]
friends <- user$getFriends()
followers <- user$getFollowers()
### Lista para passar os datos à app.analystat.com ###
myData<-list(Frecuencia=df,AsociadaR=data.frame(name=myname,y=as.numeric(associatedR$r)),Polarity=sentimentsPolarity,TimeLinePolarity=result,User=user$toDataFrame()[,c(2,3,4,5)])
### Url da aplicación ###
url<-"https://app.analystats.com/api/24421902328004610/topics/24/content/upload"
### Enviando os dados para app.analystats ###
r <- POST(url, body = myData, encode = "json",authenticate("YourUser","YourPass"))O resultado é visto abaixo
Veja o Dash-Board completo em AnalyStats => Go to Demo => Twitter Dashboard/Ver. Para ter acesso à demonstração do nosso app, escreva para [email protected].