Segmentación de clientes, o segmentación de mercado, es el proceso de dividir una base de clientes en subgrupos homogéneos dentro de una mercado heterogéneo de forma orientada al marketing. Ese agrupamiento permite a las empresas comprender sus clientes y orientar la toma de decisiones hacia grupos bien definidos, atendiendo las necesidades especificas en cada uno de ellos. Es posible, por ejemplo, identificar los grupos de clientes más lucrativos, permitiendo que la organización se concentre en mantener esos clientes.
El análisis RFM (Recency-Frequency-Monetary ou Recencia-Frecuencia-Monto) es una técnica ampliamente utilizada en identificación de clientes significativos. En este proceso, son seleccionados los clientes más recientes (R), los clientes más frecuentes (F) y el valor facturado (M) por ellos en la empresa. Más específicamente:
R: Tiempo desde la ultima compra. Es un importante predictor dado que clientes que compraron recientemente presentan mayor probabilidad de volver a comprar y responder a promociones que aquellos que compraron hace mucho tiempo atrás.
F: Número de compras realizadas por un cliente en un intervalo determinado de tiempo. Si un cliente compra frecuentemente, se espera que él vuelva a comprar.
M: Valor facturado en la empresa en un intervalo de tiempo. Aquellos clientes que gastaron mucho tienen mayor valor para la organización que aquellos que gastaron poco.
En el análisis RFM existen diferentes tipos de segmentación. En este contexto, sugerimos once segmentos ya presentados en la literatura. Sin embargo, la determinación de estos debe ser de acuerdo con la realidad de cada compañía. La siguiente tabla presenta la descripción de cada segmento. La terminología usada es una traducción libre del ingles.
| Segmentos | Descripción | R | F | M |
|---|---|---|---|---|
| Campeones | Compraron recientemente, compran con frecuencia y gastan mucho | 4-5 | 4-5 | 4-5 |
| Clientes fieles | Gastan mucho y responden a promociones | 2-5 | 3-5 | 3-5 |
| Potencialmente fieles | Compraron recientemente, más de una vez y gastaron una buena cuantía | 3-5 | 1-3 | 1-3 |
| Nuevos clientes | Compraron recientemente, pero no compran con frecuencia | 4-5 | <=1 | <=1 |
| Prometedores | Compraron recientemente, pero no gastaron mucho | 3-4 | <=1 | <=1 |
| Necesitan atención | Recencia, frecuencia y valor monetario arriba de la media | 2-3 | 2-3 | 2-3 |
| A punto de riesgo | Recencia, frecuencia y valor monetario abajo de la media | 2-3 | <=2 | <=2 |
| En riesgo | Gastaron mucho, compraron muchas veces, pero hace mucho tiempo | <=2 | 2-5 | 2-5 |
| No puede perderlos | Compraron mucho y con frecuencia, pero hace mucho tiempo | <=1 | 4-5 | 4-5 |
| Hibernando | Compraron poco, con baja frecuencia y hace mucho tiempo | 1-2 | 1-2 | 1-2 |
| Perdidos | Recencia, frecuencia y valores monetarios bajos | <=2 | <=2 | <=2 |
Implementación de RFM en Knime
En la bibliografía existen diversas aplicaciones de RFM utilizando diferentes sofwtare, la mayoría de ellas son hechas en R o Python. Como ya comentamos en el post anterior, Knime es una plataforma de código abierto para minería y análisis de datos. Nosotros proponemos aquí hacer uso de Knime para desarrollar un análisis de RFM utilizando la base de datos E-Commerce Data facilitada por UCI Machine Learning Repository. La base de datos contiene las transacciones ocurridas entre 01/12/2010 e 09/12/2011 para una tienda minorista online con sede y registro en el Reino Unido. La descripción de las variables de la base de datos es presentada a continuación:
Para el desarrollo de este estudio, utilizamos tan solo algunas de las variables presentes en la base datos:
| Variable | Descripción | Clasificación de la variable |
|---|---|---|
| ID-Cliente | Número de 5 dígitos atribuido a cada cliente | Nominal |
| Fecha de factura | Día y hora de cada transacción | Numérica |
| Cantidad | Cantidad comprada de cada producto (item) por transacción | Numérica |
| Precio unitario | Precio del producto por unidad en libras esterlinas | Numérica |
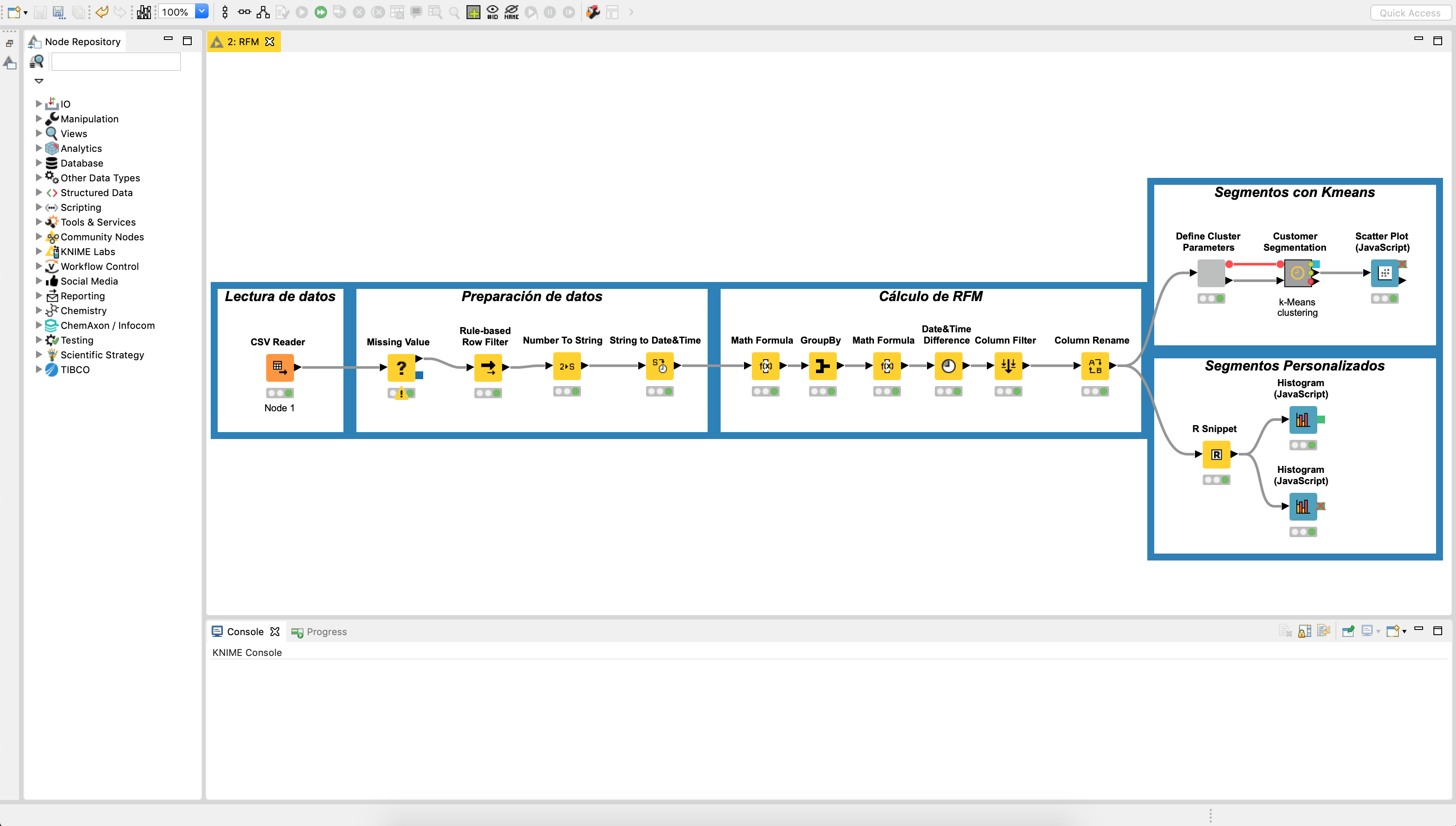
La implementación de RFM en Knime se realiza en cuatro etapas
- Lectura de los datos: Utilice un nodo para leer los datos de acuerdo al formato en el cual están almacenados.
- Depuración de los datos: Utilice nodos que permitan limpiar los datos, por ejemplo, eliminar NAs y dejar los datos en formatos adecuados.
- Cálculo de las variables RFM: Con los datos listos para el análisis, calcule para cada cliente las variables de Recencia, Frecuencia y Valor Monetario.
- Cálculo del Score y definición dos segmentos: La clasificación atribuida a cada cliente es dada de acuerdo con el quintil al cual pertenece. Por ejemplo, suponga que un cliente pertenece al 20% de los clientes que compraron más reciente, al 20% de los que menos veces han comprado y al 20% de los que menos gastaron. Eso corresponde al 5º quintil de Recencia, 1º quintil de Frecuencia y al 1º de Valor Monetario. De esta forma, el RFM para ese cliente estaría definido en el segmento de “nuevo cliente”
El gráfico a continuación muestra como luce workflow para la realización de un análisis RFM en Knime.
En la siguiente tabla se muestra el resultado para algunos clientes.
| ID Cliente | Recencia | Frecuencia | Valor Monetario | Score Recencia | Score Frecuencia | Score Valor Monetario | RFM | Segmentos |
|---|---|---|---|---|---|---|---|---|
| 12346 | 348 | 1 | 77183.6000 | 1 | 1 | 5 | 115 | Perdidos |
| 12347 | 25 | 7 | 615.7143 | 5 | 5 | 5 | 555 | Campeones |
| 12348 | 98 | 4 | 449.3100 | 2 | 4 | 4 | 244 | Clientes fieles |
| 12349 | 41 | 1 | 1757.5500 | 4 | 1 | 5 | 415 | Perdidos |
| 12350 | 333 | 1 | 334.4000 | 1 | 1 | 3 | 113 | Perdidos |
| 12352 | 59 | 8 | 313.2550 | 3 | 5 | 3 | 353 | Clientes fieles |
Con los clientes ya segmentados, podemos inicialmente revisar la cantidad de ellos en cada segmento y la proporción que representan dentro de la base de datos. Posteriormente analizar las distribuciones de la Recencia, Frecuencia y Valor Monetario.
En los boxplots observamos que la distribución del Valor Monetario es más simétrica y dispersa que la distribución de Recencia y Frecuencia. También en términos de simetría, la Frecuencia es más asimétrica que la Recencia, siendo ambas positivas.
Nuestro interés ahora es validar conjuntamente las tres variables dentro de cada segmento. Para eso, graficamos cada uno de los grupos, donde el diámetro del circulo es proporcional al valor monetario de cada cliente.
Como era esperado, los segmentos Hibernando, En riesgo, A punto de riesgo y Necesitan atención, presentan frecuencias bajas (compraron como máximo quince veces). Sin embargo, seria interesante ampliar el análisis en el grupo de clientes perdidos, ya que se observan clientes que compran muchas veces y recientemente, pero que gastan en media poco. Un examen más minucioso del perfil de esos clientes podría ser útil en acciones de marketing para recuperarlos.
Los segmentos Clientes fieles y Campeones presentan frecuencias similares, así como valor monetario, excepto que el ultimo grupo tiene un cliente con mayor frecuencia.
Otra alternativa seria aplicar sobre las variables del RFM un algoritmo de cluster basado en distancias. Por ejemplo, usar el algoritmo K-means, como es propuesto por [1]. Este procedimiento podría ayudar a entender mejor las reglas de clasificación y por ende tener mayor entendimiento de cada segmento.
Observe que el algoritmo de K-means agrupa los clientes dando mayor importancia a la Recencia. Sin embargo, seria interesante ampliar el análisis en el cluster 1, ya que se observa que el algoritmo detecto que, ademas de tener una Recencia baja, tiene una Frecuencia más alta que los otros grupos.
Referencias
[2] Hebbali A, RFM - Customer Level Data, 2019.
[3] M Hendra Herviawan, Customer Segmentation using RFM Analysis (R), 2019.
Ver también
- Business Analytics en Knime
- Un estudio al precio de arrendamiento en Medellin por medio un modelo de arbol de regresion
- Google Form: Importando datos en R y publicando resultados en AnalyStats-App
- Analizar datos de Youtube a través de R y AnalyStats-App
- Analizar datos de Twitter a través de R y AnalyStats-App