Los datos de la red social Twitter disponibles a través de su API (Application Programming Interface) proporcionan una gran cantidad de información en tiempo real. Descargar datos de la API de Twitter es relativamente sencillo, solo necesitamos crear una aplicación en https://dev.twitter.com (My app) y posteriormente obtener un API key, un API secret, un token de acceso y un Token Secret de acceso (para tener más detalle de como crear una app puede consultar aqui). En este post hicimos uso de la guia desarrollada por Yanchang Zhao Twitter Data Analysis with R para realizar un resumen de la cuenta de Twitter del cientifico de datos Kirk Borne a través de R y para posteriormente presentar los resultados en un Dash-Board de app.analystats.com. El código de R es:
### Paquetes necesarios ###
library("httr")
library('ROAuth')
library('RCurl')
library("twitteR")
library("base64enc")
library("tm")
library("topicmodels")
library("data.table")
library("xts")
library("sentiment")
library("stringr")
library("SnowballC")
###### Autenticación ######
options(httr_oauth_cache=T)
reqURL <- "https://api.twitter.com/oauth/request_token"
accessURL <- "https://api.twitter.com/oauth/access_token"
authURL <- "https://api.twitter.com/oauth/authorize"
consumerKey <- "XXXXXXXXXX"
consumerSecret <- "XXXXXXXXXX"
access_token<-"XXXXXXXXXX"
access_secret<-"XXXXXXXXXX"
twitCred <- OAuthFactory$new(consumerKey=consumerKey,consumerSecret=consumerSecret,requestURL=reqURL,accessURL=accessURL,authURL=authURL)
download.file(url="https://curl.haxx.se/ca/cacert.pem", destfile="cacert.pem")
twitCred$handshake(cainfo="cacert.pem")
setup_twitter_oauth(consumerKey, consumerSecret, access_token, access_secret)
###### Descarga de twetts ######
tweets <- userTimeline("KirkDBorne", n = 3200)
###### Convierte tweets en DataFrame ######
tweets.df <- twListToDF(tweets)
### Se construye el corpus y se indica la fuente del vector de caracteres ###
myCorpus <- Corpus(VectorSource(tweets.df$text))
### Extrae los hashtags ###
Hashtags <- function(x) str_extract_all(x, "#\\S+")
myHashtags <- tm_map(myCorpus, content_transformer(Hashtags))
### Limpiar el texto ###
### Eliminan Caracteres gráficos ###
usableText=function(x) str_replace_all(x,"[^[:graph:]]", " ")
myCorpus <- tm_map(myCorpus, content_transformer(usableText))
### Pasamos todo el texto a minuscula ###
myCorpus <- tm_map(myCorpus, content_transformer(tolower))
### Elimina hashtags ###
removeHashtags <- function(x) gsub("#\\w+", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeHashtags))
### Elimina URLs ###
removeURL <- function(x) gsub("http[^[:space:]]*", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeURL))
### Elimina letras y espacios del ingles ###
removeNumPunct <- function(x) gsub("[^[:alpha:][:space:]]*", "", x)
myCorpus <- tm_map(myCorpus, content_transformer(removeNumPunct))
### Elimina stopwords ###
myStopwords <- c(stopwords("en"),"s","w","d","u","e","x","b","rt","use", "see", "used", "via", "amp","also")
myCorpus <- tm_map(myCorpus, removeWords, myStopwords)
### Elimina espacios en blanco extra###
myCorpus <- tm_map(myCorpus, stripWhitespace)
### Una copia para completar el stem posteriormente ###
myCorpusCopy <- myCorpus
### Stem de las palabras ###
myCorpus <- tm_map(myCorpus, stemDocument)
stemCompletion2 <- function(x, dictionary) {
x <- unlist(strsplit(as.character(x), " "))
x <- x[x != ""]
x <- stemCompletion(x, dictionary=dictionary)
x <- paste(x, sep="", collapse=" ")
PlainTextDocument(stripWhitespace(x))
}
myCorpus <- lapply(myCorpus, stemCompletion2, dictionary=myCorpusCopy)
myCorpus <- Corpus(VectorSource(myCorpus))
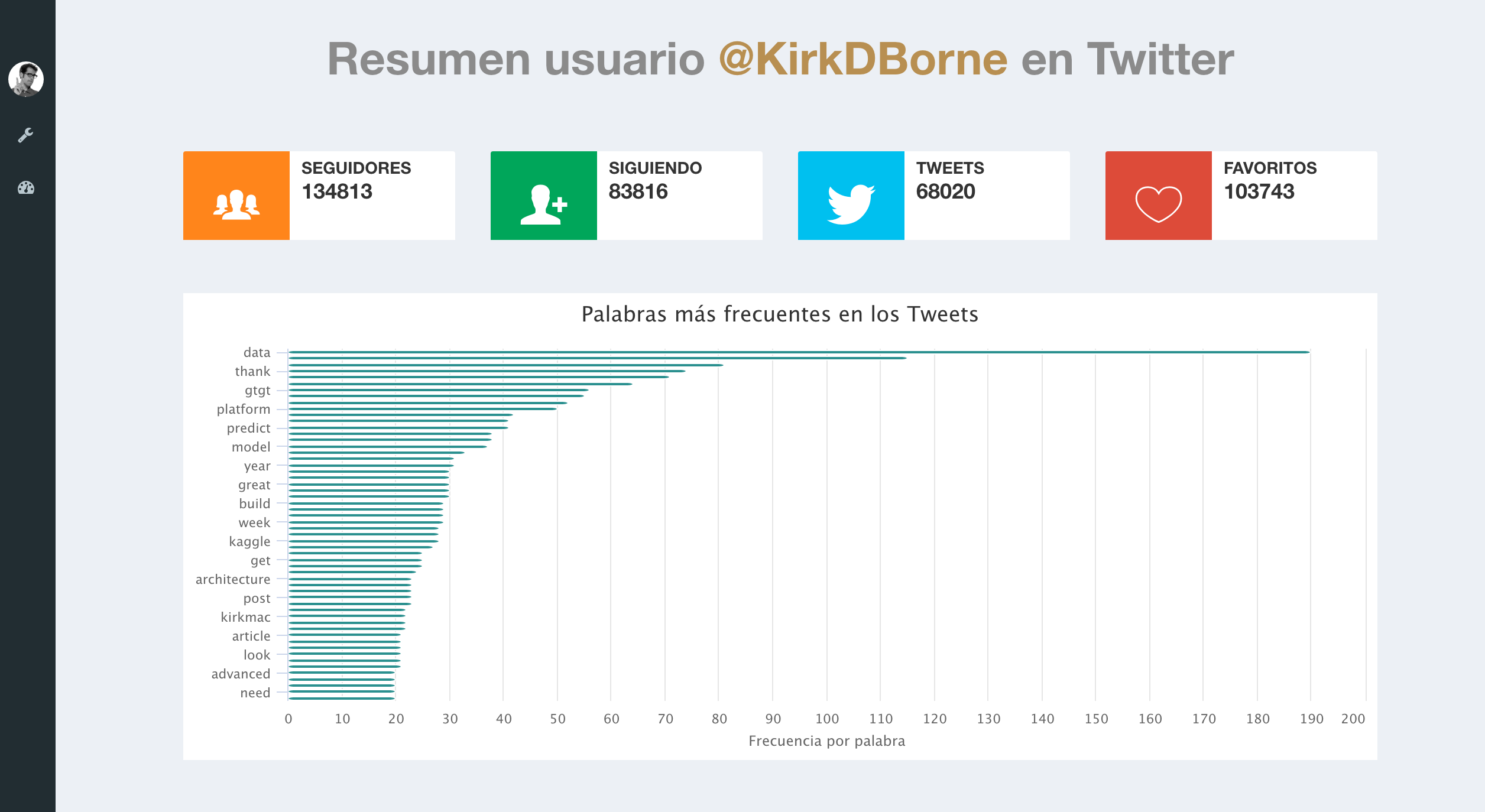
### Frecuencia de las palabras ###
tdm <- TermDocumentMatrix(myCorpus, control = list(wordLengths = c(1, Inf)))
term.freq <- rowSums(as.matrix(tdm))
term.freq <- subset(term.freq, term.freq >= 20)
df <- data.frame(term = names(term.freq), freq = term.freq,row.names = NULL)
df <- df[with(df, order(-freq)), ]
### Reemplazar algunas palabras ###
replaceWord <- function(corpus, oldword, newword){
tm_map(corpus, content_transformer(gsub),
pattern=oldword, replacement=newword)
}
myCorpus <- replaceWord(myCorpus, "miner", "mining")
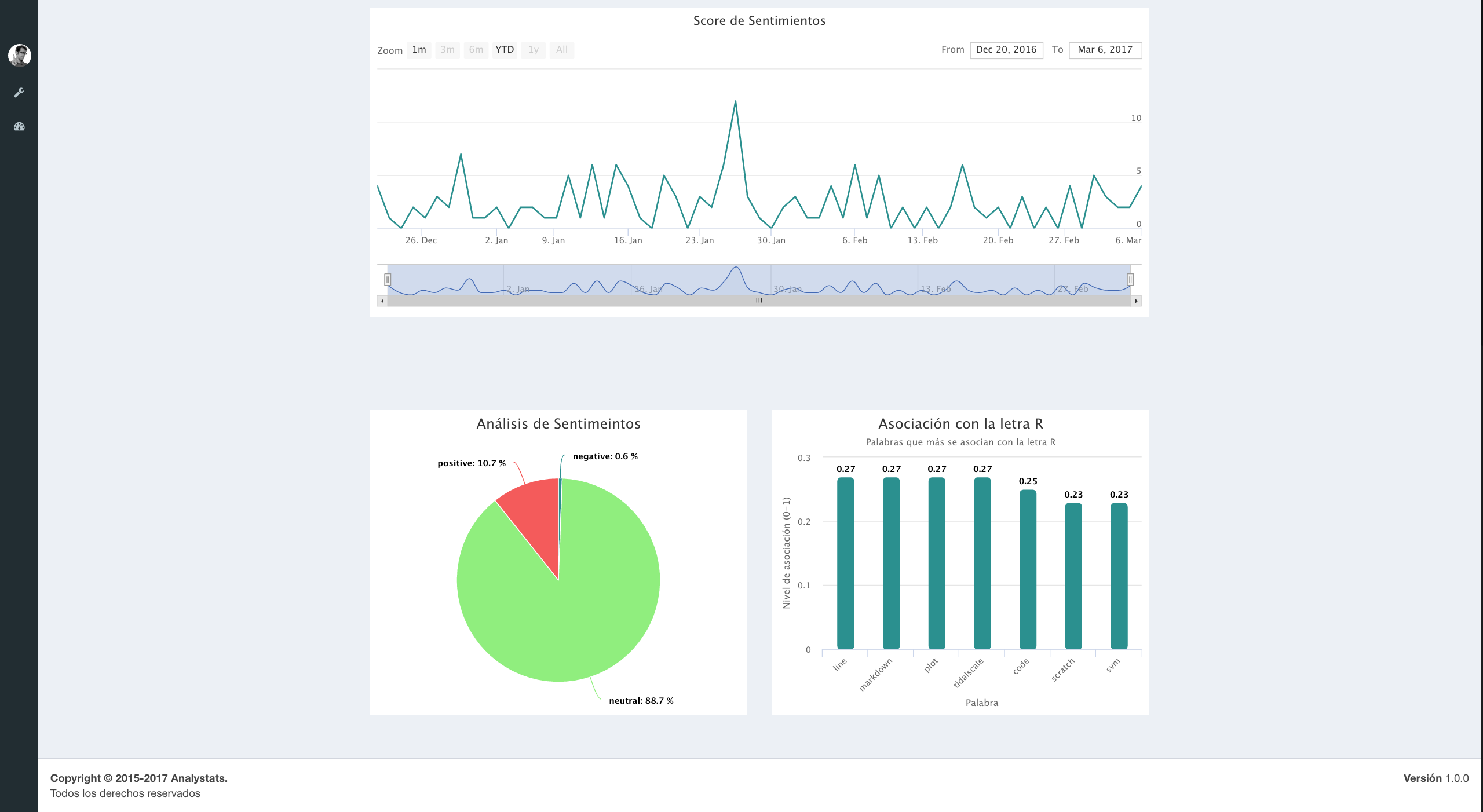
### Cuáles palabras estan asociadas con la letra R ? ###
associatedR <- findAssocs(tdm, "r", 0.2)
myname<-attributes(associatedR$r)$names
### Cuáles palabras estan asociadas con la palabra 'data'? ##
associatedData <- findAssocs(tdm, "data", 0.2)
### Análisis de sentimientos ###
sentiments <- sentiment(tweets.df$text)
sentimentsPolarity<-as.data.frame(round(prop.table(table(sentiments$polarity))*100,1))
### Linea de tiempo ###
sentiments$score <- 0
sentiments$score[sentiments$polarity == "positive"] <- 1
sentiments$score[sentiments$polarity == "negative"] <- -1
sentiments$score[sentiments$polarity == "neutral"] <- 0
sentiments$date <- as.IDate(tweets.df$created)
result <- aggregate(score ~ date, data = sentiments, sum)
### Información del Usuario ###
user <- getUser("KirkDBorne")
user$toDataFrame()[,c(2,3,4,5)]
friends <- user$getFriends()
followers <- user$getFollowers()
### Lista para pasar los datos a app.analystat.com ###
myData<-list(Frecuencia=df,AsociadaR=data.frame(name=myname,y=as.numeric(associatedR$r)),Polarity=sentimentsPolarity,TimeLinePolarity=result,User=user$toDataFrame()[,c(2,3,4,5)])
### Url de la aplicación ###
url<-"https://app.analystats.com/api/24421902328004610/topics/24/content/upload"
### Enviando los datos para app.analystats ###
r <- POST(url, body = myData, encode = "json",authenticate("YourUser","YourPass"))El resultado luce así:
Puedes ver Dash-Board completo en AnalyStats => Go to Demo => Twitter Dashboard/Ver. Si estas interesado en probar nuestra app escribenos a [email protected].